yolov1原理学习与代码复现
背景介绍
YOLO (You Only Look Once) 已经用了很久了,但是一直没有去深入挖掘其背后的原理。于是,就有了这次探索,从yolov1版本学起。
YOLO之所以叫这个名字,大概率是因为,人类看一眼图像就能立即知道图像中的物体是什么。
在当年,YOLO在进行预测时能够对图像进行全局推理,且速度极快。
论文解读
论文arxiv链接 You Only Look Once: Unified, Real-Time Object Detection
推理过程
先解读一下推理的过程和约定的参数含义。
在论文中提到,首先将输入的图像划分为 $S \times S$ 个小网格 (如 $S=7$,$7 \times 7$),模型推理会得到若干个检测框,如果检测框的中心点落入一个网格中,我们就认为这个网格负责这个框的检测。
每个网格都负责 $B$ 个检测框 (中心都落入这个网格内),因此最多能检测出 $S \times S \times B$ 个检测框,在yolov1中 $B=2$。
每个检测框可以用 $(x,y,w,h,c)$ 这五个量来描述,代表矩形框的中心点为 $(x,y)$,宽为 $w$,高为 $h$,用 $c$ 代表"框内确实有物体"的置信度 (confidence)。
对于每个网格,会用一个大小为30的张量 (Tensor)来描述:$(x_{1},y_{1},w_{1},h_{1},c_{1},x_{2},y_{2},w_{2},h_{2},c_{2},p_{1},p_{2},...,p_{20})$。
前面10个量很好理解,就是 $B=2$ 个检测框的 $5 \times 2=10$个属性,而后面的20个 $p_{n}$ 则代表了20种类别的条件概率 $P(Class_{i} | Object)$,也就是"在框内有物体的条件下,该物体是第 $i$ 个类别的概率"。从这里可以看出来,默认了一个网格内 $B$ 个检测框的类别是一致的,只是它们框选的置信度 $c_{i}$ 不同,那么对于一个网格内,两个检测框内"有第 $i$ 个类别物体"的概率分别为 $ c_{1} \times p_{i} $ 和 $ c_{2} \times p_{i} $。
至于为什么是20个类别,因为论文中使用的PASCAL VOC数据集就包含20种类别,比如说Car, Bus, Cat, Person之类的。
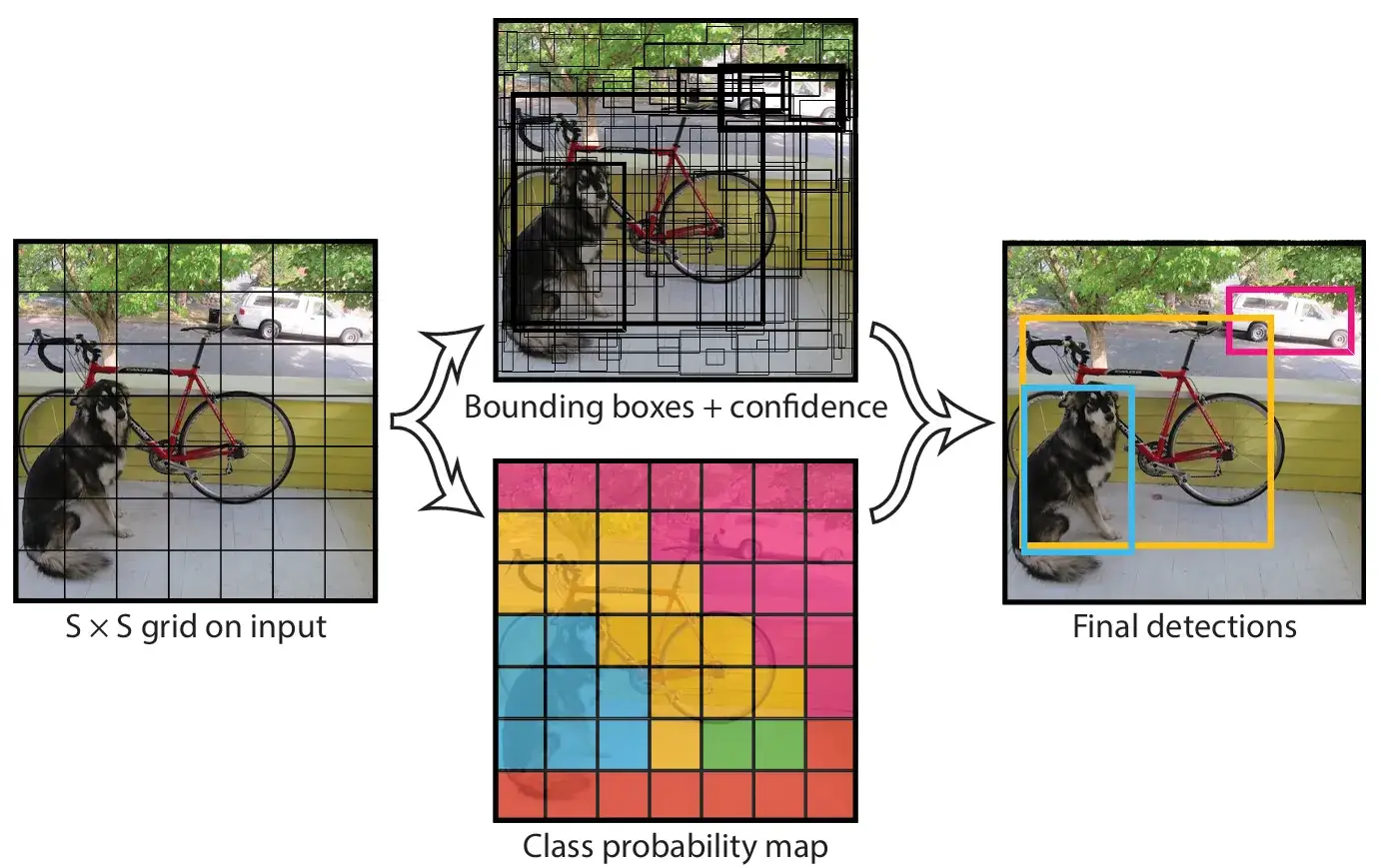
如图所示,"Class probability map"就是将每个格子最有可能的物体类别 (也就是 $p_{i}$ 最大的类别) 用对应颜色可视化出来,"Bounding boxes + confidence"则是把 $7 \times 7 \times 2=98$ 个检测框都标出来了,边线粗的代表框选置信度 $c_{i}$ 高。
那么为了得到最终的"Final detections",可以用NMS非极大值抑制的方法,本质上就是如果有两个框重叠度非常高,那就可以认为它们是同一个对象,去掉置信度更低的那一个。
具体来说,将98个检测框按置信度从高到低排序后,两两之间计算交并比$IoU=\frac{交集面积}{并集面积}$ (这样完全重叠时IoU就是1),如果大于一个阈值就可以把置信度低的删去,时间复杂度 $O(n^2)$。
卷积神经网络
网络结构
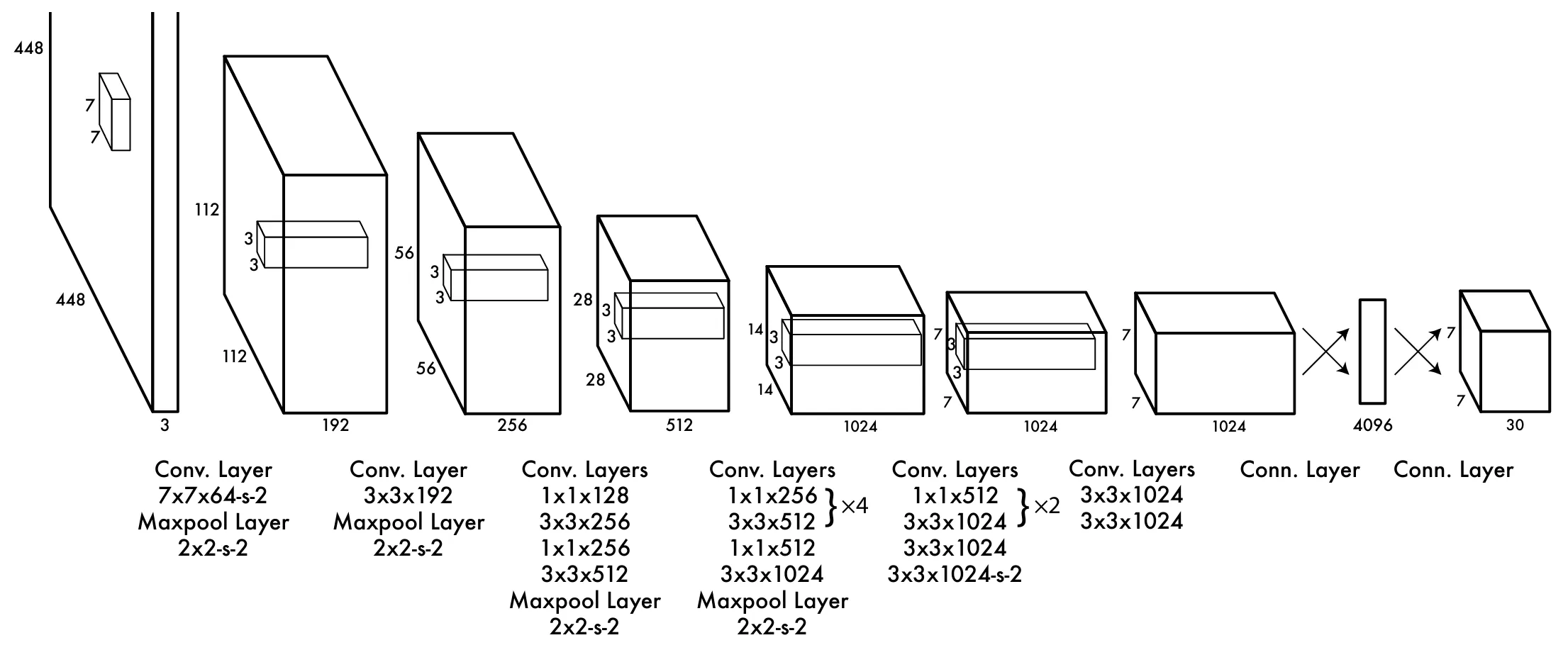
受到GoogLeNet启发,论文配图描述了网络的结构,输入448x448 RGB三通道的图像。使用了多种卷积核尺寸(7x7, 3x3, 1x1),总共24个卷积层,还使用了 2x2 池化层进行下采样 (降维压缩)。最后两个全连接层,得到推理的结果 $7 \times 7 \times 30$ 张量。
卷积的理解
概率论中计算连续型随机变量之和的概率密度函数,需要用到卷积公式 $\int_{-\infty}^{\infty} f(\tau) g(t - \tau) \, d\tau$,本质上是一种加权平均。
而图像处理用到的二维卷积是 $f * g(x, y) = \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f(u, v) g(x - u, y - v) \, du \, dv$,其实说白了就是两个函数在每个位置相乘累加,如果把 $g(x,y)$ "旋转180度"($x-u$ 和 $u$ 互换,$y-v$ 和 $v$ 互换),离散地来看,那其实就是$f * g[m, n] = \sum_{i=0}^{M-1} \sum_{j=0}^{N-1} f[i, j] \cdot g[i, j]$。
我们把 $g$ 用一个矩阵表示,叫做卷积核,比如说是 $$ \begin{bmatrix} 1 &0 &1 \\ 0 &1 &0 \\ 1 &0 &1 \end{bmatrix} $$
然后我们让这个卷积核在 $f$ 矩阵上"滑动",这样可以算出9个值,如下面动画所示 (假设偏置为0):
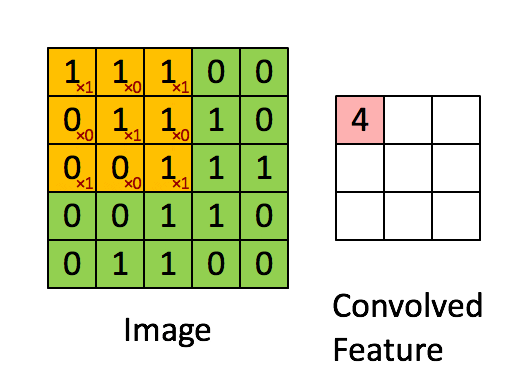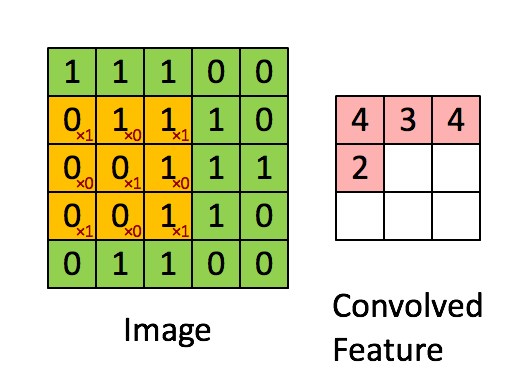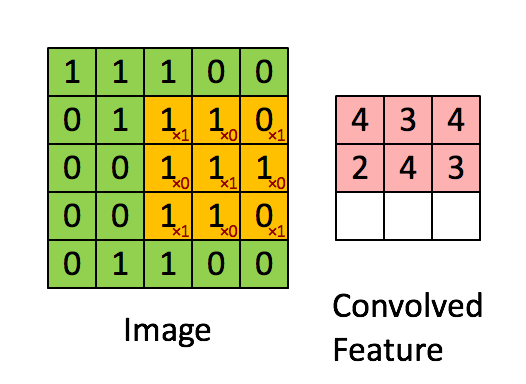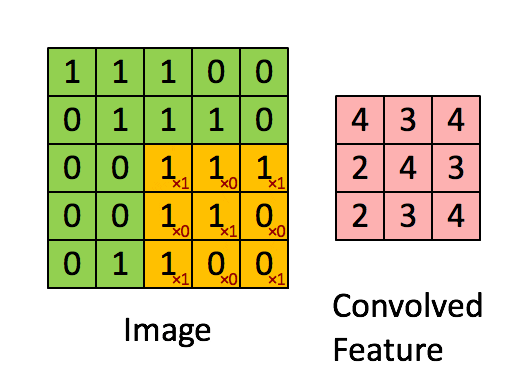
那这有什么用呢?卷积又被称为滤波器 (Filter)。对一张图像数据进行不同的卷积操作,可以得到很多种神奇的效果:

比如说边缘检测的卷积核:
$$ \begin{bmatrix} -1 &-1 &-1 \\ -1 &8 &-1 \\ -1 &-1 &-1 \end{bmatrix} $$
之所以能达到这种效果,是因为如果一个像素周围像素值和它几乎相等,那么它应该不是边缘点,这一块卷积之后结果就是0。
人们可以设计出不同的卷积核,对图片进行不同的处理。从锐化边缘提取我们可以看出来,卷积核有利于提取图像的一些"特征"。
深度学习的出现使得不再需要人工设计卷积核,卷积核本质是一些参数,可以通过机器学习训练得到。把卷积层引入神经网络就变成了卷积神经网络。
我的理解为,容易发现卷积是线性运算,理论上全连接层也可以达到这种效果,但是用卷积操作极大简化了网络参数量 (相当于连接更稀疏了),尤其是我们认为它能反映图像的特征,在计算机视觉中很有效。
以上说的是单通道单卷积核的操作,实际上用的是多通道多卷积核。
比如说用3x3卷积核把一个3通道RGB图像卷积得到16通道的输出,是如何进行的?
就是用了16个3x3卷积核,各分别得到一个通道输出,注意每个卷积核有3层 (和输入通道数一致,是3,所以共48个3x3矩阵),
考虑其中一个卷积核的三层分别叫$W_{Ri}, W_{Gi}, W_{Bi}$,那么用 $W_{Ri}$ 对R通道进行卷积,用 $W_{Gi}$ 对G通道进行卷积,用 $W_{Bi}$ 对B通道进行卷积,得到三个矩阵,把它们相加,再加上一个偏置值,就得到一个通道的卷积结果,16个通道都是这么来的。
下图展示了从 $C$ 个通道的输入卷积得到 $FN$ 个通道输出的过程,使用 $FN$ 个 $C$ 层卷积核进行操作。
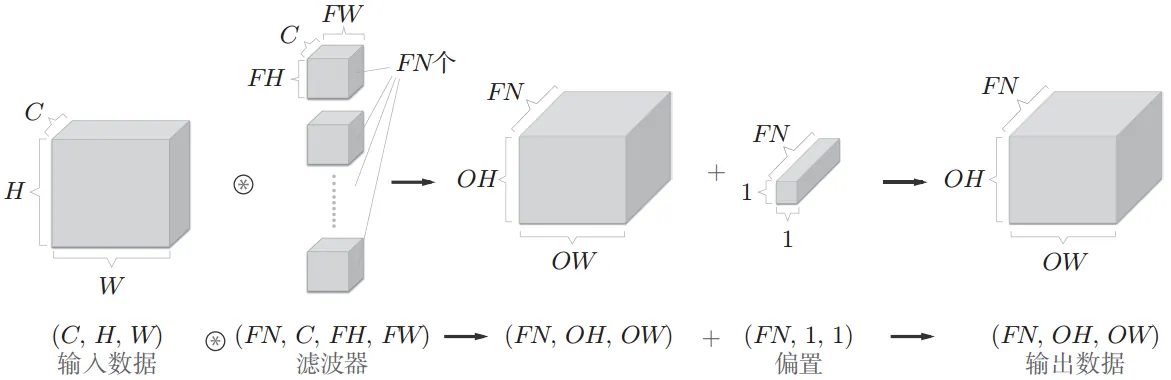
卷积核滑动的时候还有步长 $S$ (Stride) 和填充 $P$ (Padding) 参数,不过多解释。
如果一个卷积核高 $k_h$,宽 $k_w$,那么输出的尺寸为:
$$ \begin{cases} H_{out} = \frac{H_{in} + 2P - k_h}{S} + 1 \\ W_{out} = \frac{W_{in} + 2P - k_w}{S} + 1 \end{cases} $$
总之,不同的卷积核可以理解为从不同视角去"提取特征"。
Loss函数设计
如论文所述,loss function是五部分相加。
下述 $\mathbf{1}_{i}^{\text{obj}}$ 表示物体出现在 (应该意思是只要网格内有一个检测框负责就行) 网格 $i$ 中时为1,否则为0,$\mathbf{1}_{ij}^{\text{obj}}$ 表示网格 $i$ 中的第 $j$ 个检测框负责该预测时为1,否则为0。同理"noobj"上标和"obj"含义是反的。
注意,一个网格中有 $B$ 个检测框,和标注数据 IoU 最大的那个检测框才是对其负责的。
检测框中心点定位误差
$\lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}_{ij}^{\text{obj}} \left[ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 \right]$
很好理解,就是遍历所有的检测框,如果这个框内有负责的物体,就加上与标定值的平方和误差。
检测框尺寸误差
$\lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}_{ij}^{\text{obj}} \left[ \left( \sqrt{w_i} - \sqrt{\hat{w}_i} \right)^2 + \left( \sqrt{h_i} - \sqrt{\hat{h}_i} \right)^2 \right]$
宽和高的误差,之所以这里要开根号,是为了突显小框的误差,想象一下,一个边长30的正方形预测成29,和一个边长3的正方形预测成2,哪个更严重?显然是小尺寸的检测框偏差1像素更致命,而开根就让这种误差更敏感。
有物体时的置信度误差
$\sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}_{ij}^{\text{obj}} \left( C_i - \hat{C}_i \right)^2$
如果标定的数据集中这个框内有负责的物体,那么 $P(object)=1$,这里的 $\hat{C}_i=P(object) \times IoU_{truth}^{pred}=IoU_{truth}^{pred}$,也就是矩形框和数据集中标定框的交并面积之比。
无物体时的置信度误差
$\lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}_{ij}^{\text{noobj}} \left( C_i - \hat{C}_i \right)^2$
如果标定的数据集中这个框没有负责的物体,那么 $\hat{C}_i=0$。
有物体时的类别概率误差
$\sum_{i=0}^{S^2} \mathbf{1}_{i}^{\text{obj}} \sum_{c \in \text{classes}} \left( p_i(c) - \hat{p}_i(c) \right)^2$
如果数据集对这个网格标注的类别为 $c$,那么应该是只有 $\hat{p}_i(c)$ 为1,其他 $\hat{p}_i$ 都为0。
也有变种实现使用的是交叉熵损失。
权重说明
注意到存在 $\lambda_{\text{coord}}$ 和 $\lambda_{\text{noobj}}$,论文中的解释为,在图像中许多网格单元不包含任何物体,这会将这些单元格的置信度推向零,通常会压倒包含物体的单元格的梯度,可能会导致模型训练不稳定。所以就设置$\lambda_{\text{coord}}=5, \lambda_{\text{noobj}}=0.5$,以降低无物体误差的权重。
代码复现
模型结构实现
再放一遍图,使用Pytorch编写,复刻图示结构:
用表格梳理:
| 模块 | 操作说明 | 输出尺寸 (H×W×C) |
|---|---|---|
| 输入 | RGB 图像 | 448×448×3 |
| conv1 | 7×7 大卷积核,stride=2,输出 64 通道,提取粗特征 | 224×224×64 |
| pool1 | MaxPool(2×2, stride=2),缩小一半 | 112×112×64 |
| conv2 | 3×3 卷积,stride=1,输出 192 通道 | 112×112×192 |
| pool2 | MaxPool(2×2, stride=2) | 56×56×192 |
| conv3 | 一组 [1×1, 3×3, 1×1, 3×3],通道扩展到 512 |
56×56×512 |
| pool3 | MaxPool(2×2, stride=2) | 28×28×512 |
| conv4 | 多组 [1×1, 3×3] 堆叠,最后扩展到 1024 通道 |
28×28×1024 |
| pool4 | MaxPool(2×2, stride=2) | 14×14×1024 |
| conv5 | [1×1, 3×3] 堆叠,空间缩小到 7×7,保持在 1024 通道,最后一个 3×3 stride=2 下采样 |
7×7×1024 |
| conv6 | 两个 3×3 卷积,输出仍是 1024 通道 | 7×7×1024 |
最后的全连接层使用线性激活函数,其他部分全部使用参数为0.1的LeakyReLU激活函数:
$$ \phi(x) = \begin{cases} x, & \text{if } x > 0, \\ 0.1x, & \text{otherwise} \end{cases} $$
import torch
import torch.nn as nn
class Block(nn.Module):
def __init__(self, layers_param, use_pool=True):
super().__init__()
layers = []
for in_ch, out_ch, k_size, stride, padding in layers_param:
layers.append(nn.Conv2d(in_ch, out_ch, k_size, stride, padding, bias=False))
layers.append(nn.LeakyReLU(0.1))
self.conv = nn.Sequential(*layers)
self.pool = nn.MaxPool2d(2) if use_pool else None
def forward(self, x):
x = self.conv(x)
if self.pool is not None:
x = self.pool(x)
return x
class DarkNet(nn.Module):
def __init__(self):
super(DarkNet, self).__init__()
self.conv1 = Block([[3, 64, 7, 2, 3]])
self.conv2 = Block([[64, 192, 3, 1, 1]])
self.conv3 = Block([
[192, 128, 1, 1, 0],
[128, 256, 3, 1, 1],
[256, 256, 1, 1, 0],
[256, 512, 3, 1, 1]
])
self.conv4 = Block([
[512, 256, 1, 1, 0],
[256, 512, 3, 1, 1],
[512, 256, 1, 1, 0],
[256, 512, 3, 1, 1],
[512, 256, 1, 1, 0],
[256, 512, 3, 1, 1],
[512, 256, 1, 1, 0],
[256, 512, 3, 1, 1],
[512, 512, 1, 1, 0],
[512, 1024, 3, 1, 1]
])
self.conv5 = Block([
[1024, 512, 1, 1, 0],
[512, 1024, 3, 1, 1],
[1024, 512, 1, 1, 0],
[512, 1024, 3, 1, 1],
[1024, 1024, 3, 1, 1],
[1024, 1024, 3, 2, 1]
], use_pool=False)
self.conv6 = Block([
[1024, 1024, 3, 1, 1],
[1024, 1024, 3, 1, 1]
], use_pool=False)
# 初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='leaky_relu')
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
return x
if __name__ == "__main__":
x = torch.randn(1, 3, 448, 448)
net = DarkNet()
print(net)
out = net(x)
print(out.shape)
直接运行,会输出网络的结构,同时测试得到输出shape为torch.Size([1, 1024, 7, 7]),张量大小是对的,说明网络没问题。
预训练
按论文所述,模型首先在ImageNet数据集上进行预训练,参与预训练的模型并不是前面图示完整的模型结构,而是前20个卷积层+1个平均池化层+1个全连接层,且参与输入图像尺寸是244x244。预训练完成后,再添加4个卷积层和2个全连接层,将输入增加到448x448,用完整的结构在PASCAL VOC数据集上进行微调训练,以实现目标检测。
通俗来说就是,我们认为图像分类和目标检测两种任务具有相似性,让模型先在大型数据集ImageNet (1000种类别) 上"学习图像的特征",用学到的权重参数来初始化卷积层,这样能加速后面的训练,同时能增强模型的泛化能力。
论文中提到他们用了大约一周的时间来完成预训练,由于数据集太大且耗时长,我们可以利用ResNet50预训练权重的一部分,并对其进行修改以模拟替代这个结构 (详细参见GitHub上有人写的这个pytorch实现 https://github.com/EclipseR33/yolo_v1_pytorch,其部分实现与原论文存在差异):
import torch
from torchvision.models.resnet import ResNet, Bottleneck
class ResNet_(ResNet):
def __init__(self, block, layers):
super(ResNet_, self).__init__(block=block, layers=layers)
def _forward_impl(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.maxpool(x)
x = self.layer3(x)
x = self.maxpool(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(block, layers, pretrained):
model = ResNet_(block, layers)
if pretrained is not None:
state_dict = torch.load(pretrained)
model.load_state_dict(state_dict)
return model
def resnet_1024ch(pretrained=None) -> ResNet:
resnet = _resnet(Bottleneck, [3, 4, 6, 3], pretrained)
return resnet
if __name__ == '__main__':
x = torch.randn([1, 3, 448, 448])
net = resnet_1024ch('resnet50-19c8e357.pth')
print(net)
y = net(x)
print(y.size())
ResNet50预训练权重从pytorch官网下载resnet50-19c8e357.pth。
再用表格看看每层的效果:
| 模块 | 操作说明 | 输出尺寸 (H×W×C) |
|---|---|---|
| 输入 | RGB 图像 | 448×448×3 |
| conv1 | 7×7 卷积,stride=2,输出 64 通道 | 224×224×64 |
| maxpool | 3×3 池化,stride=2 | 112×112×64 |
| layer1 | 3 个 Bottleneck,输出 256 通道 | 112×112×256 |
| layer2 | 4 个 Bottleneck,第一个 stride=2,下采样 | 56×56×512 |
| 额外 maxpool | 3×3 池化,stride=2 | 28×28×512 |
| layer3 | 6 个 Bottleneck,第一个 stride=2,下采样 | 14×14×1024 |
| 额外 maxpool | 3×3 池化,stride=2 | 7×7×1024 |
原有的layer4和后面的部分删去,相当于利用了ResNet的部分结构,继承重写了原有的类,额外添加两个池化层,使得最终输出尺寸和yolov1结构的一致。
有可能是拼接了ResNet的原因,这样训练出来权重会比较大 (900多MB)。
数据预处理
首先获取数据集,现在可以从这里下载,Kaggle PASCAL VOC 2007 and 2012。
在Annotations目录里,有每张图片的标注数据,类似这样:
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size>
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
可以看到包含了每个object的类别名称,还有框选的xmin, ymin, xmax, ymax坐标。
这种XML格式可以用python的xml模块进行解析。然后要实现一个yolo类,首先需要对数据集进行解析,详见注释:
def label2grid(self, label):
"""
将原始标注(xmin, ymin, xmax, ymax, class)转换为所需网格格式。
YOLOv1 假设每个网格最多一个目标,所以这里只保留第一个落入该网格的目标。
:param label: Tensor,形状 [N, 5],每行为 [xmin, ymin, xmax, ymax, class_id]
:return: List,长度为 S*S。每个元素为:
- None:该网格无目标
- Tensor [1, 5]:该网格有目标,格式 [cx, cy, w, h, class_id]
"""
# 初始化 S*S 个网格都为 None
output = [None for _ in range(self.s ** 2)]
# 计算每个网格的尺寸
size = self.image_size // self.s
# 获取标注框数量
n_bbox = label.size(0)
# 如果没有标注框,直接返回全 None
if n_bbox == 0:
return output
# 创建新张量 label_c
label_c = torch.zeros_like(label)
# 将 (xmin, ymin, xmax, ymax) 转换为中心点 + 宽高
# 中心点 x 坐标 = (xmin + xmax) / 2
label_c[:, 0] = (label[:, 0] + label[:, 2]) / 2
# 中心点 y 坐标 = (ymin + ymax) / 2
label_c[:, 1] = (label[:, 1] + label[:, 3]) / 2
# 宽度 = xmax - xmin(假设 xmax > xmin)
label_c[:, 2] = label[:, 2] - label[:, 0]
# 高度 = ymax - ymin(假设 ymax > ymin)
label_c[:, 3] = label[:, 3] - label[:, 1]
# 保留类别标签
label_c[:, 4] = label[:, 4]
# 确定每个目标中心点所属的网格索引
# idx_x[i] = 第 i 个目标中心点所在的 x 方向网格索引
idx_x = [int(label_c[i][0]) // size for i in range(n_bbox)]
# idx_y[i] = 第 i 个目标中心点所在的 y 方向网格索引
idx_y = [int(label_c[i][1]) // size for i in range(n_bbox)]
# 中心点坐标归一化,先对 size 取模,再除以 size,归一化到 [0, 1]
label_c[:, 0] = torch.div(torch.fmod(label_c[:, 0], size), size)
label_c[:, 1] = torch.div(torch.fmod(label_c[:, 1], size), size)
# 将宽高归一化到整张图像
label_c[:, 2] = torch.div(label_c[:, 2], self.image_size)
label_c[:, 3] = torch.div(label_c[:, 3], self.image_size)
# 将每个目标分配到对应的网格中
for i in range(n_bbox):
# 计算展开的一维网格索引
idx = idx_y[i] * self.s + idx_x[i]
# 如果该网格还没有目标,就放入这个目标,这样只留第一个,官方 Darknet 是覆盖为最后一个
if output[idx] is None:
output[idx] = torch.unsqueeze(label_c[i], dim=0)
return output
损失函数实现
def compute_loss(self, input, target):
"""
计算单张图像的损失
:param input: 单图模型输出,[S*S, B*5 + num_classes]
:param target: 经过 label_direct2grid_v1 处理后的标签,List[None 或 Tensor[1,5]]
:return: (总损失, xy_loss, wh_loss, conf_loss, class_loss),都是标量 tensor
"""
# 原文中的参数
lambda_coord = 5.0
lambda_noobj = 0.5
# 提取预测框部分 [cx, cy, w, h, conf]
input_bbox = input[:, :self.b * 5].reshape(-1, self.b, 5)
# 提取分类 [S*S, num_classes]
input_class = input[:, self.b * 5:]
# 对预测框坐标和置信度应用 sigmoid,约束输出归一化
input_bbox = torch.sigmoid(input_bbox)
# 初始化各网格的损失
loss = torch.zeros(1, device=self.device)
xy_loss = torch.zeros(1, device=self.device)
wh_loss = torch.zeros(1, device=self.device)
conf_loss = torch.zeros(1, device=self.device)
class_loss = torch.zeros(1, device=self.device)
for i in range(self.s ** 2):
# 当前网格无物体
if target[i] is None:
# 所有 B 个预测框的置信度都应该趋近于 0
obj_conf_target = torch.zeros(self.b, device=self.device)
conf_loss += torch.sum(lambda_noobj * (input_bbox[i, :, 4] - obj_conf_target) ** 2)
# 当前网格有物体
else:
# 计算每个预测框与标注数据的 IoU
true_box = target[i][:, :4]
pred_boxes = input_bbox[i, :, :4]
ious = self.get_iou(pred_boxes, true_box, i)
# 找到 IoU 最大的预测框,也就是"负责人"
best_box_idx = torch.argmax(ious).item()
best_iou = ious[best_box_idx]
# 中心点坐标损失
xy_loss += lambda_coord * (
(input_bbox[i, best_box_idx, 0] - target[i][0, 0]) ** 2 +
(input_bbox[i, best_box_idx, 1] - target[i][0, 1]) ** 2
)
# 尺寸损失,对 w, h 取平方根,添加 1e-8 防止 sqrt(0) 的梯度问题
wh_loss += lambda_coord * (
(torch.sqrt(input_bbox[i, best_box_idx, 2] + 1e-8) - torch.sqrt(target[i][0, 2])) ** 2 +
(torch.sqrt(input_bbox[i, best_box_idx, 3] + 1e-8) - torch.sqrt(target[i][0, 3])) ** 2
)
# 置信度损失,置信度目标 = IoU
conf_loss += (input_bbox[i, best_box_idx, 4] - best_iou) ** 2
# 注意,虽然网格内有物体,但只有一个预测框对其负责,这里还有对剩下框noobj的置信度损失
for b in range(self.b):
if b != best_box_idx: # 非负责框
conf_loss += lambda_noobj * (input_bbox[i, b, 4] - 0) ** 2
# 类别概率损失
# 创建 one-hot 目标向量
true_class = int(target[i][0, 4])
class_target = torch.zeros(self.num_classes, device=self.device)
# 只有标注类别概率为 1,其他全 0
class_target[true_class] = 1.0
class_loss += torch.sum((input_class[i] - class_target) ** 2)
loss = xy_loss + wh_loss + conf_loss + class_loss # 总损失
return loss, xy_loss, wh_loss, conf_loss, class_loss
训练过程
论文中提到:
Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from $10^{−3}$ to $10^{−2}$. If we start at a high learning rate our model often diverges due to unstable gradients. We continue training with $10^{−2}$ for 75 epochs, then $10^{−3}$ for 30 epochs, and finally $10^{−4}$ for 30 epochs.
总共135遍训练,学习率是先逐渐增大,再逐渐降低的。初始使用一个很大的学习率训练会导致数值不稳定,所以会在开始使用一个小的学习率,使参数逐渐接近解空间的大致位置,后续为了更加接近目标解,学习率会逐渐降低。
除此之外,还提到对原始数据使用了随机缩放和随机亮度色彩调整,以防止过拟合。
一个稍微简化的实现见Github仓库,实测在5060ti显卡上训练一个epoch要10分钟左右,还是有点慢的......
局限性和思考

yolov1每个网格只能预测一种目标,且最多检测98个目标,针对成群的小型物体时效果就比较差。但是在当年这种快速且准确率还不错的方法开创了新道路,YOLO的后续版本也基于此进行了若干改进。
解读完yolov1,可能会有一些问题和思考。首先为什么要得到98个检测框再进行抑制?因为CNN是有固定维度的输出张量,所以表示固定数量的框。而不同对象的位置又不一样,所以很自然地就想到划分网格单元,负责不同位置问题的检测。
那么一个网格内为什么又要多个框呢?感觉就是提供了"候选项",进行冗余预测,这样可能定位更精准。
卷积层又为什么要这么设计呢?除了让shape与预期输出一致,其实感觉还是基于经验的,能work就行(