基于SAM和DepthAnything的单目沙堆三维重建与估计
背景
由学校老师拟定的一个小课题,尝试使用计算机视觉模型解决一个实际问题:不规则堆垛体积自动估算。
这个测量一般是人工进行或者借助激光雷达进行三维重建,单目视觉方案相比之下很轻量,但是也存在尺度不确定性、信息模糊等挑战。
思路和实现
消除畸变
原始图像是用船舱上的球机采集的,可以明显感觉到图像存在畸变,使用opencv内置的鱼眼校正,微调相机参数就可以得到比较好的校正效果:

对比二者最明显的区别,就是原来弯曲的直线得以恢复。
主体分割
拿到这样的图,需要想办法聚焦主体部分,抑制背景干扰。
我选择借助SAM3 (Segment Anything) 模型进行语义分割,使用自然语言描述如"sand ship"进行目标分割。
取置信度较高的结果,得到的掩码如图中红色部分所示:
单目深度估计
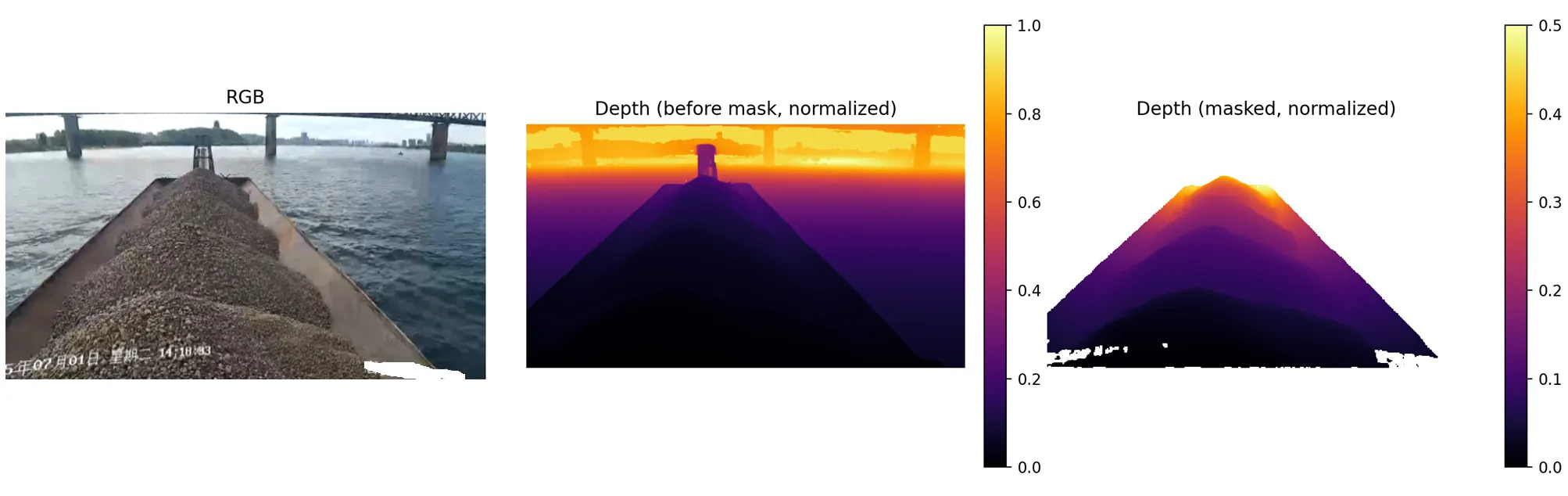
使用DepthAnything3模型进行深度估计,得到每个像素点对应的深度。这里一开始还踩了个坑,不能使用掩码抑制后的主体图像进行深度估计,因为这样会使得背景特征信息减少,从而得到很不准确的估计 (如平行线跑出来变得不平行)。
输入整张图后得到全局深度估计,再使用主体掩码对需要的区域进行提取,可视化出来是这样:
由深度图到三维点云
常用针孔相机模型来描述成像。这是由成像原理决定的,当没有小孔时,物体上所有点都向各方向发出光,重叠地映射在墙上,于是接收到的图像就是模糊的。而使用小孔成像后,就能接收到倒立的像。
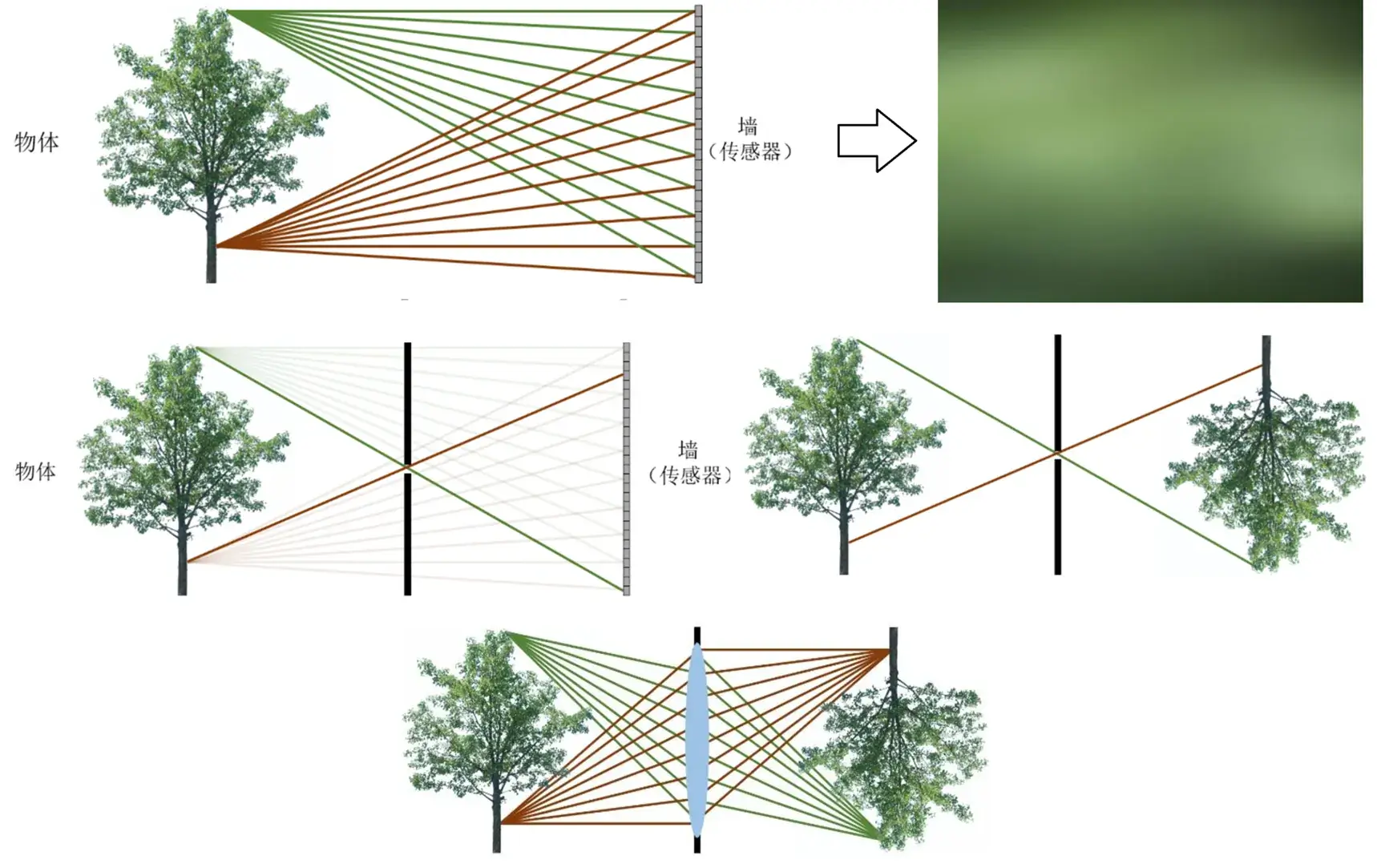
我们都知道当小孔特别小时光会发生衍射,因此相机内部实际上是用透镜实现的 (相机畸变也和透镜做工误差存在关系),但是用针孔相机模型来描述依旧很有效。
如下图,将蓝色的成像平面沿小孔对称得到一个浅色的虚拟平面,到小孔的距离也等于焦距,在这个平面上,像相对于倒立像又了旋转180度,也就是正的像。这个虚拟平面就可以看作是图像平面。
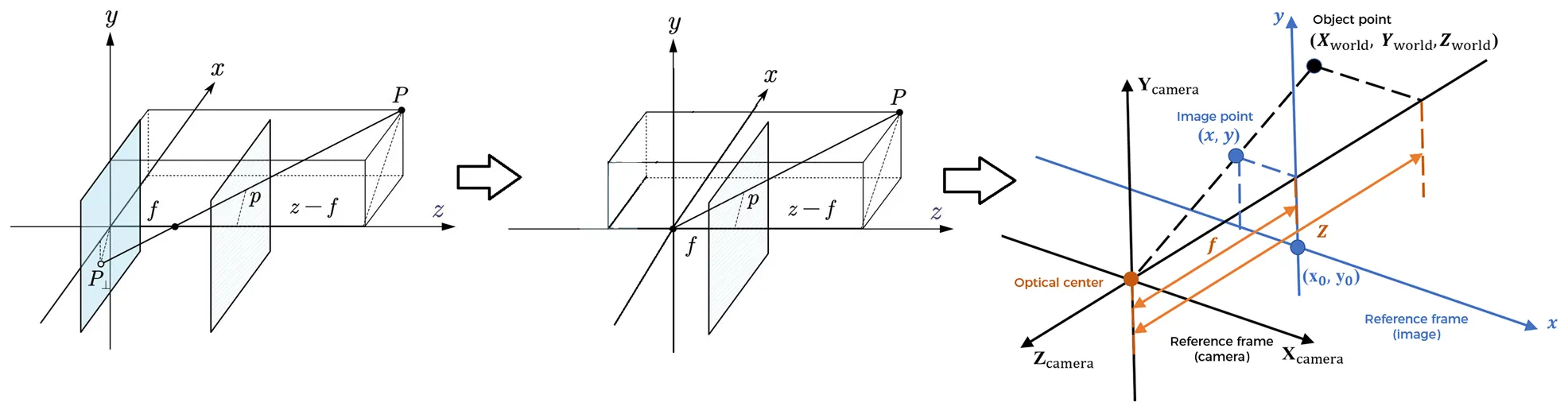
$Z$ 是图像平面上一个点 $(x,y)$ 对应的深度,那么由相似比例关系可得:
$$ \begin{cases} \frac{x - x_0}{f} = \frac{X}{Z} \\ \frac{y - y_0}{f} = \frac{Y}{Z} \end{cases} $$
于是便确定了图中一个点在三维坐标系中对应的坐标 $(X,Y,Z)$,把图中所有像素点的坐标都算出来就形成了点云。
生成的结果是这样,上表面的大致形状得以恢复:
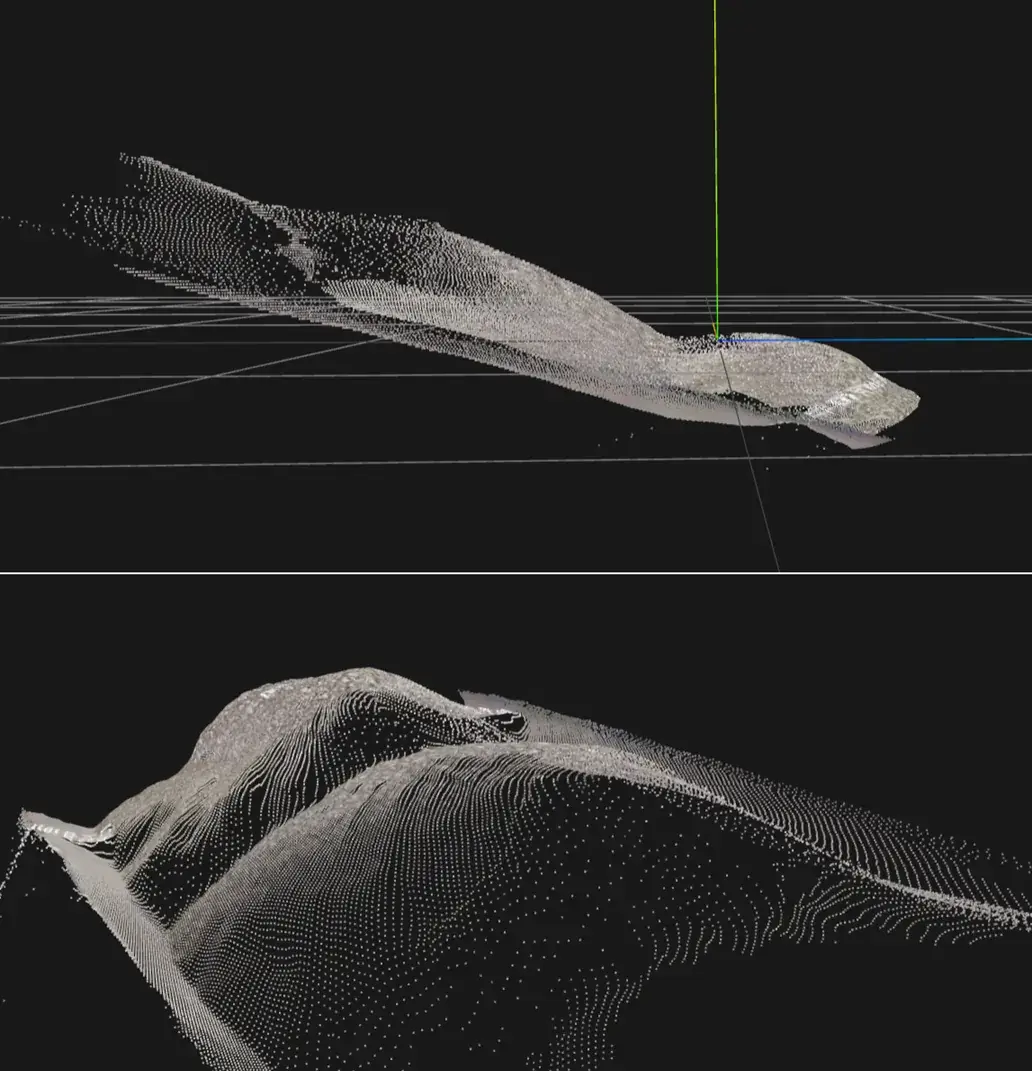
沙堆底面估计
可以看到点云是向上翘起的,现在的坐标系与预期不符。为了得到沙堆确切的高度,需要得到下底面。
RANSAC算法可以提取"内点"拟合平面,但如果直接对整个点云拟合会成这样,大概率得到一个斜的切面:
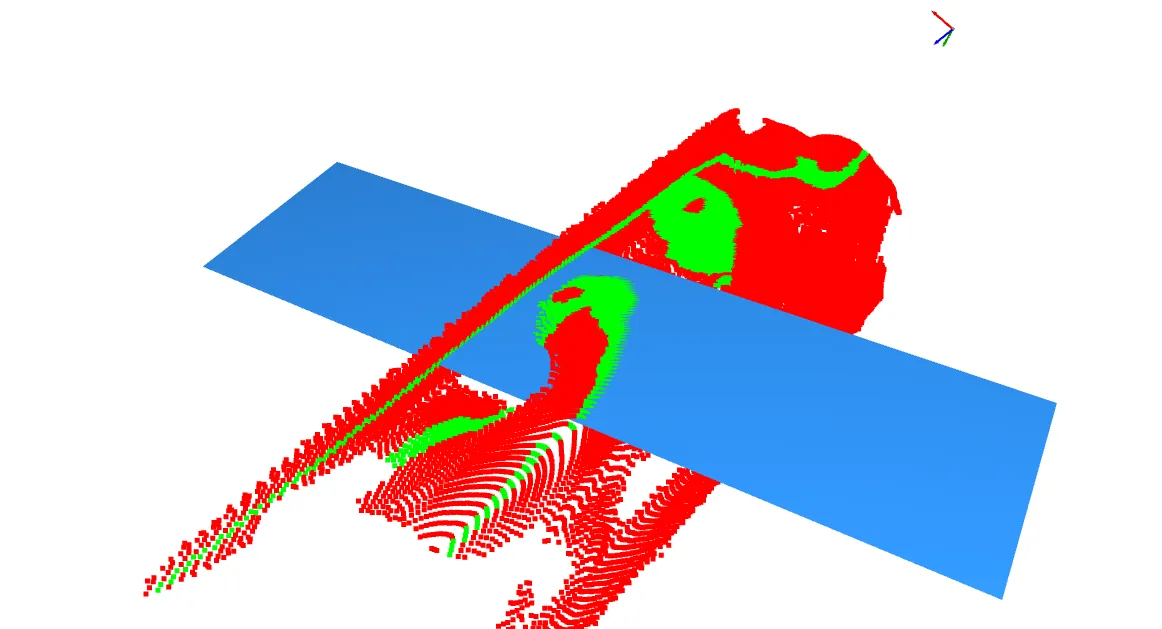
显然还是不能直接套用,需要更可靠的思路。我的想法是,既然船舱比较规则,可以利用船舱的轮廓线拟合出一个平面,作为基准面,再下移至需要的底面位置。
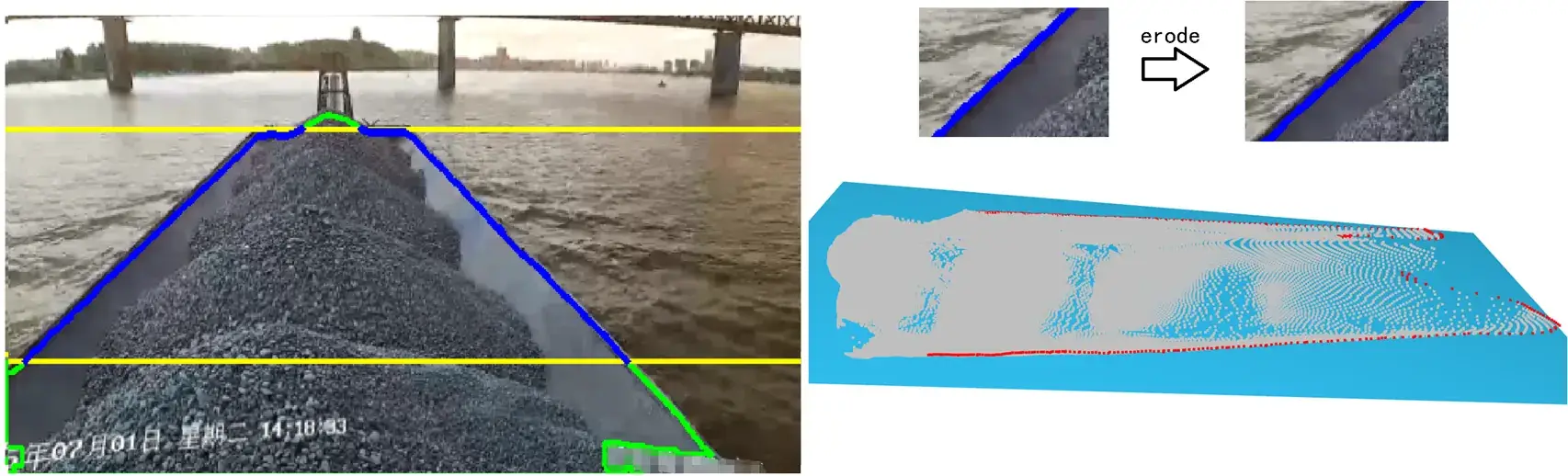
那么轮廓线恰好可以从主体掩码中获得,还是先用opencv的findContours函数找到二值化掩码的外轮廓,由于拍摄遮挡和船头凸起问题,只取中间的轮廓线视作船舱的外边缘线 (蓝线所示)。
由于轮廓是临界点,需要向内收缩几个像素以避免舱外噪点影响,直接使用opencv的erode函数对掩码边缘进行腐蚀处理。
用python的open3d模块把这些边缘点标红可视化出来,生成一个底面,效果很明显:
拟合平面用的是numpy求解SVD,将所有点减去质心 $P_{i}'=P_{i}-\overline{P}$,
构建矩阵进行奇异值分解 $A=[P_{1},P_{2},...,P_{n}]=U \Sigma V^{T} $。
取 $V$ 最后一列作为平面法向量,保证是朝上的 ($z<0$ 就取反),最后将平面与点云最低点对齐。
高度绝对尺度恢复
DepthAnything得到的是相对深度估计,也就是还得有参照物尺度才能把长度对应到现实中的单位量度。
既然船舱边缘线有了,那么舱体宽度就是一个很好的参考,假设大概为4或5米。
那么标定宽度,将点云投影到平面法向量上,每个点相对底面的高度就得到了,由于点云是稀疏的,缺失部分的高度使用scipy模块的griddata线性插值补全。
最终得到一个高度图,取底面微元进行积分就能得到体积。
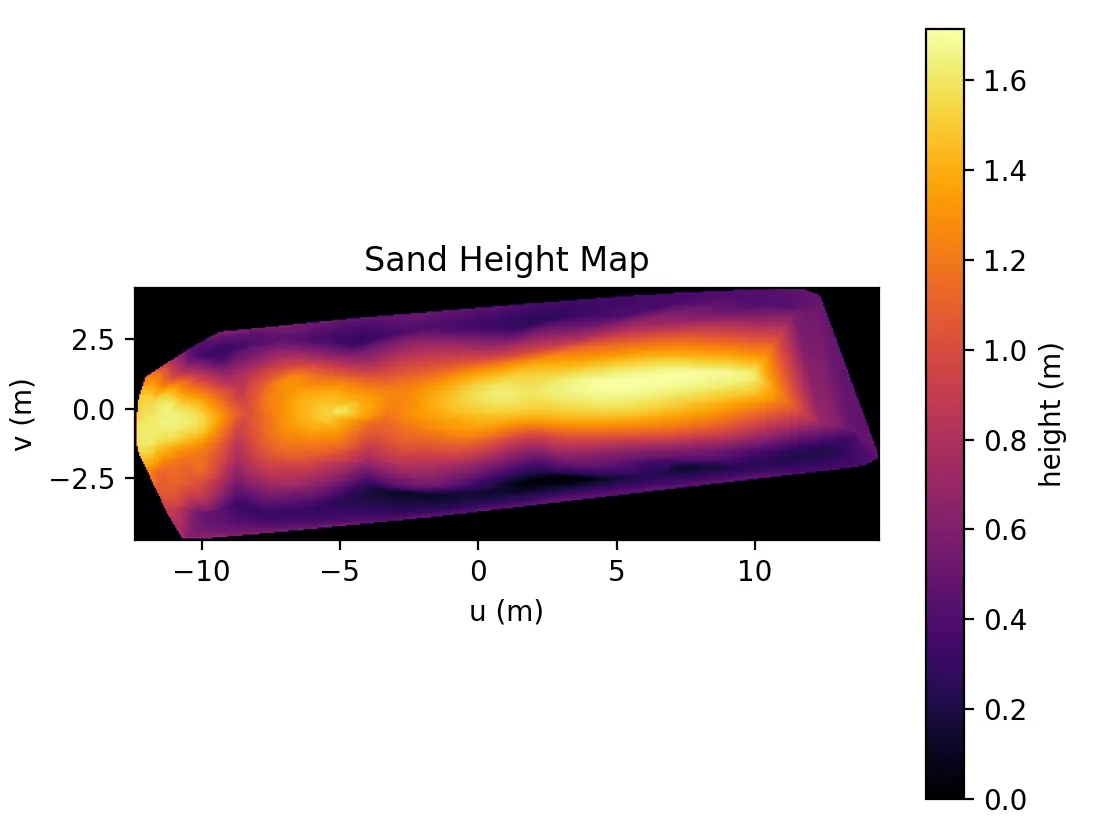
后续工作
注意到现在只得到了上表面可视部分的形状,实际上船舱底面并非是平的,而是类似一个"倒三角",因此还需要针对不可视部分进行体积预测,或者将当前点云与空船基准点云进行匹配结合。
还有就是SAM方法切割的掩码准确度对预测精度影响较大,有时可能切出来不想要的部分,如何精确地分割出想要的主体部分也是个难题 (尤其是比如图中还有别的船),实测提示词的影响也很大,在数据集较大时可以针对这一场景手动标注并对模型进行微调训练。

另外由于单目视觉的局限性,有的区域高度会很平,没准就只能用生成式脑补了(
环境搭建
最后附上环境搭建过程的记录,模型是借用一位学长的5060ti显卡跑的,CUDA 13.1版本。
使用conda管理python 3.12版本,原因是最新的3.14没有适配的open3d模块。
DepthAnything3的预训练模型可以直接从huggingface上下载,使用6.76 GB的 DA3NESTED-GIANT-LARGE-1.1 模型。而SAM3的预训练权重需要申请才能获取,建议直接从阿里的魔搭社区下载 (3.44 GB)。
DepthAnything按照官方demo改写,只用一张预处理过的test.png,可以得到每个像素点对应的深度和相机内参外参。
import glob, os, torch
from depth_anything_3.api import DepthAnything3
device = torch.device("cuda")
model = DepthAnything3.from_pretrained("model/DA3NESTED-GIANT-LARGE")
model = model.to(device=device)
prediction = model.inference(
["test.png"],
)
# prediction.processed_images : [N, H, W, 3] uint8 array
print(prediction.processed_images.shape)
# prediction.depth : [N, H, W] float32 array
print(prediction.depth.shape)
# prediction.conf : [N, H, W] float32 array
print(prediction.conf.shape)
# prediction.extrinsics : [N, 3, 4] float32 array # opencv w2c or colmap format
print(prediction.extrinsics.shape)
# prediction.intrinsics : [N, 3, 3] float32 array
print(prediction.intrinsics.shape)
而SAM的demo需要多修改一下,首先是build_sam3_image_model要传入自定义的checkpoint_path,也就是下载的pt权重的路径,load_from_HF参数传入False,bpe_path对应bpe_simple_vocab_16e6.txt.gz的位置,另外Sam3Processor类中写死了mask_threshold,原来是:
state["masks"] = out_masks > 0.5
也就是固定的0.5阈值,实测这个值需要微调,否则得到的掩码完整性可能不太理想,所以最好重写一个自定义的Sam3Processor类。
由于是Windows环境,没有triton,如果中途出现"No module named 'triton'",直接用pip install triton-windows安装别人编译好的就行。
总之就是各种依赖项要装,还有等待预训练权重下载过程,最后用GPU跑出来很快,一张图不到一秒就能完成。
效果评估
到这里,我决定换一张新图看看效果,就像"测试集"一样。
既然目标是"不规则堆垛体",那就换一个不那么规则的。
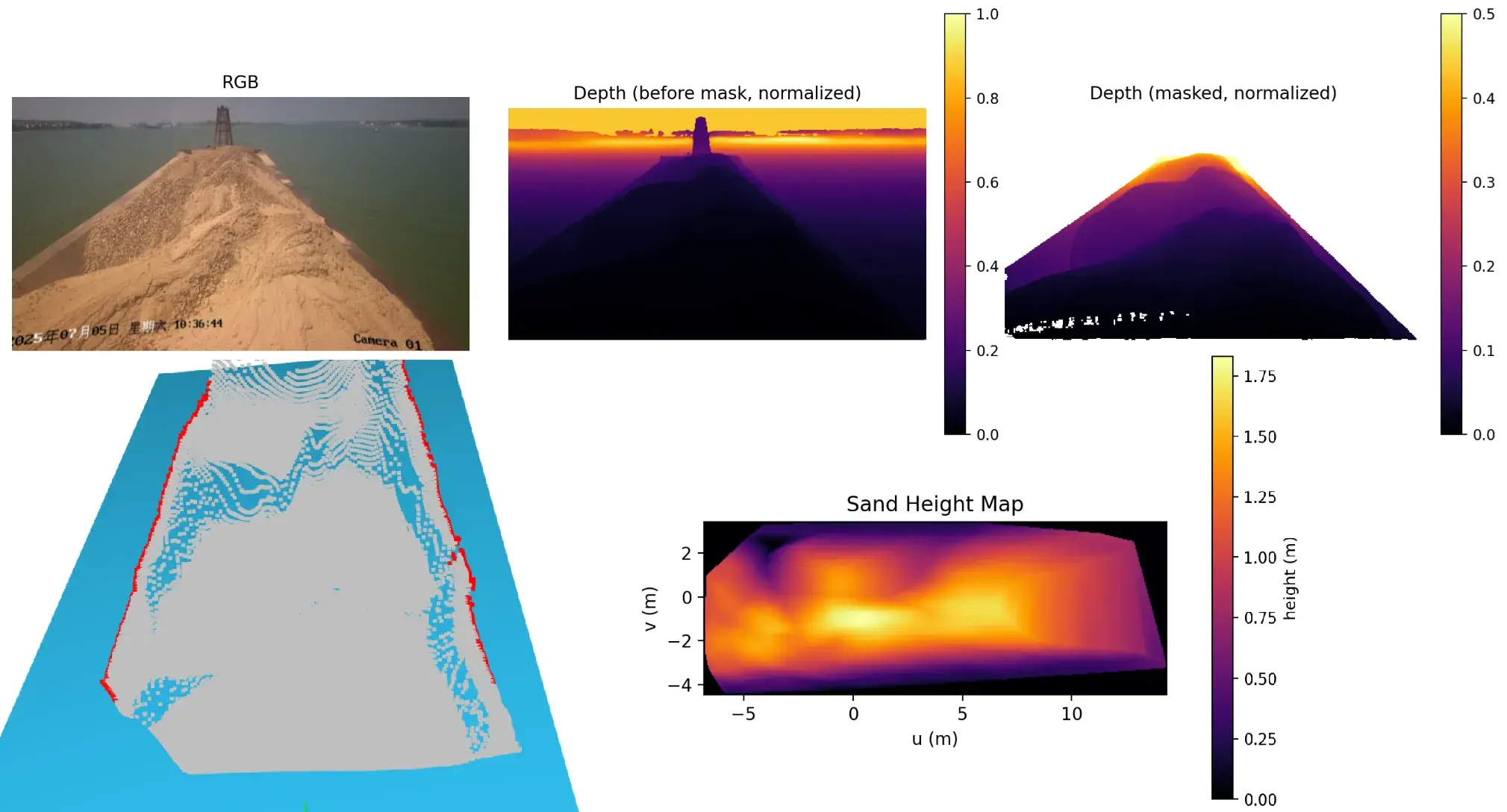
好像有那么点感觉,但是尺度估计精度又是另一回事了。总体来说,我个人感觉纯靠单目视觉完成体积估计,想要达到一个较好精度,还是比较困难的,毕竟一张图包含的信息量有限的。
主要还是多亏了SAM和DepthAnything这两大顶尖模型,能拿来直接用(
在这个过程中,也算是学到了点新东西。