首先,我们随便点进一个视频,比如说https://www.bilibili.com/video/BV1XW411M7Gu 。
查看源代码,发现__playinfo__内的信息很多,疑似关键信息,先存下来。
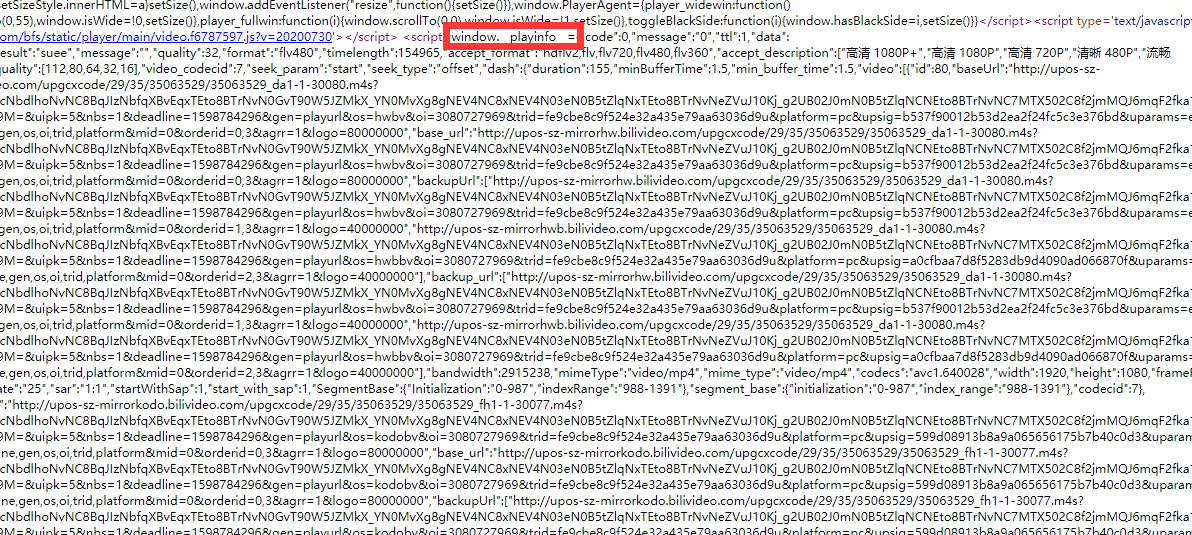 仔细分析,可以发现里面有不同分辨率的视频地址,音频地址,真是得来不费功夫。
仔细分析,可以发现里面有不同分辨率的视频地址,音频地址,真是得来不费功夫。
利用requests和re库,便可以获取到其中的内容:
import requests,re
url='https://www.bilibili.com/video/BV1XW411M7Gu'
text=requests.get(url).text
json_text=re.findall(r'<script>window.__playinfo__=(\{.*?\})</script>',text)[0]
为了方便处理,import json添加引用,接着使用一个列表将视频信息进行整理,分类成几种清晰度。
playinfo=json.loads(json_text)
video_info_list=[]
quality_len=len(playinfo['data']['accept_description'])
for i in range(quality_len):
video_info={}
video_info['quality']=playinfo['data']['accept_description'][i]
video_info['acc_quality']=playinfo['data']['accept_quality'][i]
video_info['video_url']=playinfo['data']['dash']['video'][i]['baseUrl']
video_info['audio_url']=playinfo['data']['dash']['audio'][0]['baseUrl']
video_info_list.append(video_info)
然后,定义一个download函数,调用即可完成下载:
def download(referer_url,video_url,audio_url,video_name):
headers={
'User-Agent':'Mozilla/5.0 (Windows 10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.3239.11',
'Referer':referer_url,
'Origin': 'https://www.bilibili.com',
}
#伪造headers
print("开始下载视频:%s"%video_name)
video_content=requests.get(video_url, headers=headers)
print('%s视频大小:'%video_name, video_content.headers['content-length'])
audio_content=requests.get(audio_url, headers=headers)
print('%s音频大小:'%video_name, audio_content.headers['content-length'])
#开始下载视频
received_video=0
with open('%s_video.mp4' % video_name, 'ab') as output:
while int(video_content.headers['content-length']) > received_video:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
received_video += len(response.content)
#下载视频结束,开始下载音频
audio_content=requests.get(audio_url, headers=headers)
received_audio=0
with open('%s_audio.mp4' % video_name, 'ab') as output:
while int(audio_content.headers['content-length']) > received_audio:
#视频分片下载
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
#下载音频结束
return video_name
然后调用测试:
download(url,video_info_list[0]['video_url'],video_info_list[0]['audio_url'],'test')
上面下载的是列表第一个清晰度(1080p+)的视频,效果如下:
 由于音视频是分开的,因此我们需要将其合并。
由于音视频是分开的,因此我们需要将其合并。
可以选择借助ffmpeg来进行此操作,然后运用subprocess命令行调用即可。
FFmpeg 是一个开放源代码的自由软件,可以运行音频和视频多种格式的录影、转换、流功能,包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以及libavformat——一个音频与视频格式转换库。官网https://ffmpeg.org
命令行调用ffmpeg示例:ffmpeg -i test_video.mp4 -i test_audio.mp4 -c copy out.mp4
当然,此爬虫并没有完善,还可以加入诸多功能,比如说下载进度显示、异常处理,番剧和含列表视频下载支持。
代码公开在Github,仓库地址:https://github.com/hlwdy/pybilibili