仅供测试参考,不要浪费洛谷大量服务器资源,后果自负。
首先,我们随便打开一个题目,比如说最简单的 P1000 ,
查看源代码,我们会发现,所有的题目内容都在article里面:
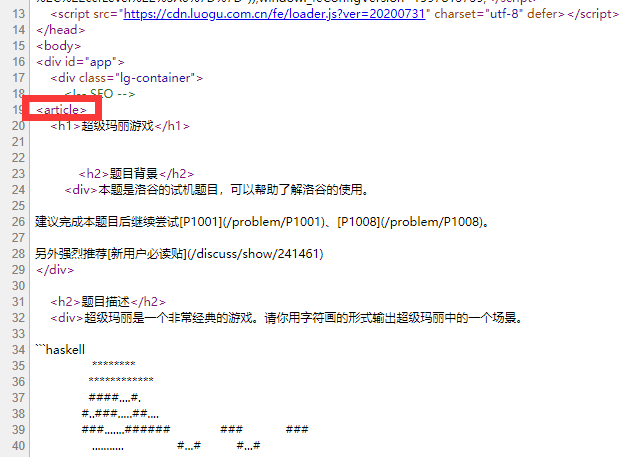 分析到这里,爬取题目内容就很简单了。
分析到这里,爬取题目内容就很简单了。
首先引用BeautifulSoup
from bs4 import BeautifulSoup
然后编写一个函数,用来获取指定id的题目内容。
def getContent(id):
url='https://www.luogu.com.cn/problem/'+id
ip={'proxy':'http:\\175.42.68.43:9999'}
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.2924.87 Mobile Safari/537.36',
}
html=requests.get(url,headers=headers,proxies=ip).text
soup=BeautifulSoup(html,"html.parser")
result=soup.find('article').get_text()
return result
这里还使用了伪造headers和代理。
然后我们调用这个函数,比如说getContent('P1001')即可。
利用python,我将一部分洛谷的题目成功爬下来,并收入了mongodb数据库中。
利用数据库,以后便可以很轻松地查询某个题目。
最后提醒:不要浪费洛谷大量服务器资源,不要过分爬取洛谷内容,请遵守爬虫协议。