Transformer原理学习
学习一下大名鼎鼎的 Transformer 架构,众所周知,GPT系列模型就是建立在 Transformer 基础上的。
论文arxiv链接 Attention Is All You Need
同时推荐一个3Blue1Brown的可视化讲解视频 直观解释注意力机制,Transformer的核心,视频里面将语义向量和Transformer的注意力机制处理过程直观地展示出来了。
从RNN引入
在人们用深度学习处理序列数据 (如文本、语音序列) 的早期,循环神经网络 (RNN) 及其变体长期占据主导地位。
这种序列数据存在着上下文关联性,比如说翻译一个多义词时,它的意思和前后文应该存在关系。
RNN的核心思想很直观,正如其名"循环",拆开来就是若干个重复节点串连,它相当于引入了时序,通过一个隐藏状态,在上一轮和这一轮之间传递信息,从而"记住"过去的内容。这种结构天然契合序列的时序特性,也因此在机器翻译等任务中取得了很多成效。
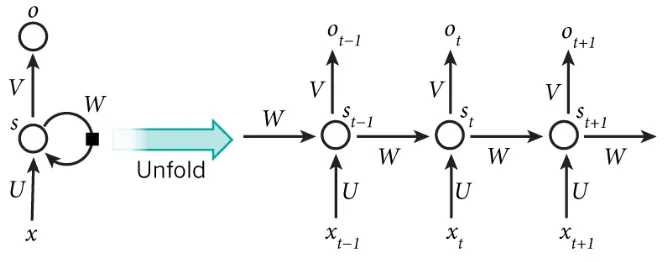
RNN每轮的输出不仅和这轮输入有关,还和上一轮的输出有关,一个接一个Token输入进去,这决定了RNN的计算必须是串行的。因此RNN的训练通常比较慢,限制了模型在大规模数据上的可扩展性。
于是,研究者开始探索新的架构,Google Brain团队提出了完全依赖注意力机制的Transformer架构。
核心思想是,序列中的每个元素都应该能直接"关注"到其他所有元素,而无需通过中间步骤逐步传递信息。
这种设计带来了全局上下文感知,且所有位置可以同时计算 (高度并行化),极大地加速了训练过程。
Transformer总体结构
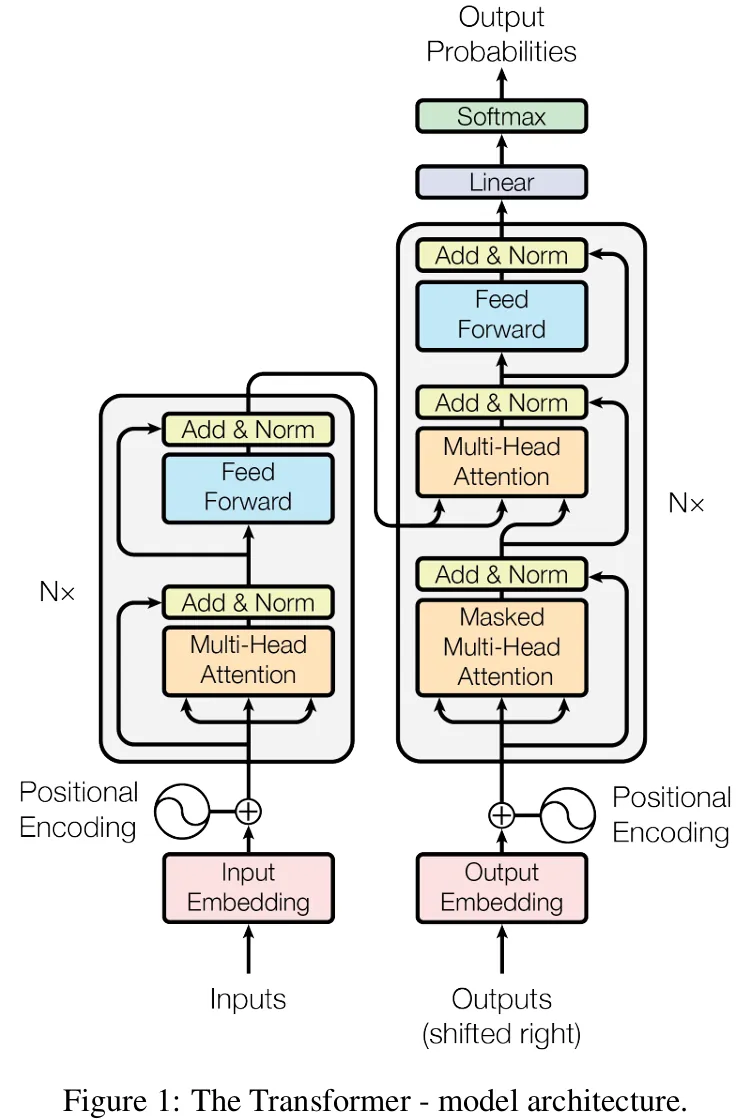
首先来分析论文中这张图,主体是Encoder-Decoder结构,
图中左侧 $N=6$ 个编码器 (Encoder) 负责"理解"输入序列 (例如将一句英文提取成一系列富含语义的向量),每个编码器有两个子模块。
图中右侧 $N=6$ 个解码器 (Decoder) 负责"生成"输出序列 (例如根据这些向量逐词生成对应的中文翻译),每个解码器有三个子模块。
"Embedding"指的是一种将离散变量 (如单词) 转换为连续向量表示的方法,说白了就是本质上有一个巨大的查找表,将单词 ID 映射成一个固定维度的向量。
"Add & Norm"指的是 $Output=LayerNorm(x+Sublayer(x))$,就是引入残差结构 (参见ResNet,$x+f(x)$ 的结构),再进行归一化 (LayerNorm)。
注意到图中还有"Multi-Head Attention" (多头注意力)、"Masked Multi-Head Attention"、"Feed Forward" (前馈网络)、"Positional Encoding" (位置编码),这些在论文后面有解释。
因此,后面的内容都围绕这个结构展开,逐步拆解各部分。
缩放点乘注意力机制
公式
论文中提到的 "Scaled Dot-Product Attention",也就是 Transformer 中使用的注意力机制,公式为:
$$\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V$$
整篇论文中的向量都是行向量表示,其中:
$Q \in \mathbb{R}^{n \times d_k}$: 查询 (Query) 矩阵,$n$ 是序列长度 (如句子中词的数量),$d_k$ 是每个 query/key 向量的维度,
$K \in \mathbb{R}^{m \times d_k}$: 键 (Key) 矩阵,(自注意力时 $m = n$),
$V \in \mathbb{R}^{m \times d_v}$: 值 (Value) 矩阵,
$\frac{1}{\sqrt{d_k}}$: 缩放因子。
Q,K,V的理解
想象一下,假如说我们要找有关深度学习的书,应该怎么检索?搜索关键词"深度学习",看看每本书的书名和"深度学习"相似程度如何。
query就是我们的查找,key就是书名,它们都是向量,要计算它们的相似程度,可以直接用点积相似度 (将两个向量做点乘运算来反映相似度),这样如果两个向量方向相反,点积为负就是极其不相关的。
把所有的 $n$ 个query向量合在一起写成一个矩阵 $Q$,把所有的 $m$ 个key向量合在一起写成一个矩阵 $K$,那么 $QK^T \in \mathbb{R}^{n \times m}$ 就是计算所有的点积相似度,得到一张 $n \times m$ 的表,即不同 query 和 key 两两配对之间的相似度。
简单写一下表示就是这样 (都是行向量):
$$Q=\begin{bmatrix} q_1 \\ q_2 \\ \dots \\ q_n \end{bmatrix}, K^T=[k_1,k_2,\dots,k_m]$$
$$ QK^T= \begin{bmatrix} q_1 \cdot k_1^T & q_1 \cdot k_2^T & \dots & q_1 \cdot k_m^T \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & \dots & q_2 \cdot k_m^T \\ \dots & \dots & \dots & \dots \\ q_n \cdot k_1^T & q_n \cdot k_2^T & \dots & q_n \cdot k_m^T \end{bmatrix} $$
而value向量就代表了"书的内容",固定一个query,就可以对所有书的value加权求和,即相似度大的书value占的权重也大。
具体来说,就是用softmax将相似度转化为概率分布 (即注意力权重),
$$ \begin{aligned} z=(z_1,z_2,\dots,z_n) \\ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} \end{aligned} $$
这样每一行的概率值相加总和 $\sum_{j=1}^{n} p_{i,j}$ 都是1,最后乘以 $V$ 加权求和得到 $n$ 个行向量,就是 $n$ 个查询得到的加权混合 $v'$ 向量:
$$ \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V= \begin{bmatrix} p_{1,1} & p_{1,2} & \dots & p_{1,m} \\ p_{2,1} & p_{2,2} & \dots & p_{2,m} \\ \dots & \dots & \dots & \dots \\ p_{n,1} & p_{n,2} & \dots & p_{n,m} \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \\ \dots \\ v_m \end{bmatrix} =\begin{bmatrix} v'_1 \\ v'_2 \\ \dots \\ v'_n \end{bmatrix} $$
缩放因子
注意到还有个缩放因子,为什么要除以 $\sqrt{d_k}$ 来缩放?
当维度 $d_k$ 较大时,query 和 key 的点积 $q k^T$ 的方差会比较大。经过 softmax 后,这些大数值会使 softmax 输出趋近于 one-hot(也就是极端稀疏,比如说 softmax([10, 2, -5]) $\approx$ [0.9997, 0.0003, 0]),而 softmax 在饱和区导数近似为0,梯度变得极小,导致训练困难。
假设 $q, k \in \mathbb{R}^{d_k}$,且各维度分量 (设为 $q_i, k_i$) 独立同分布,$q_i, k_i \sim \mathcal{N}(0, 1)$,
则 $q k^T = \sum_{i=1}^{d_k} q_i k_i$,每一项 $q_i k_i$ 的方差为 $\text{Var}(q_i)\text{Var}(k_i) = 1 \times 1 = 1$
所以总和的方差为 $d_k$,标准差为 $\sqrt{d_k}$,那么除以标准差就可以标准化缩放。
自注意力和交叉注意力
自注意力 (Self-Attention) 解决了一个序列内部的上下文建模问题,就像是让句子中的每个词都提出自己的问题 (Query),倾听所有其他词的自我介绍 (Key),然后根据匹配度决定该听谁的发言 (Value),最后综合各方意见形成自己的最终观点,因此 $n=m$。
交叉注意力 (Cross-Attention) 解决了序列之间的信息交互问题,就是让一个序列去关注 (Query) 另一个不同的序列 (Key和Value),比如从一种语言到另一种语言的翻译就需要它。
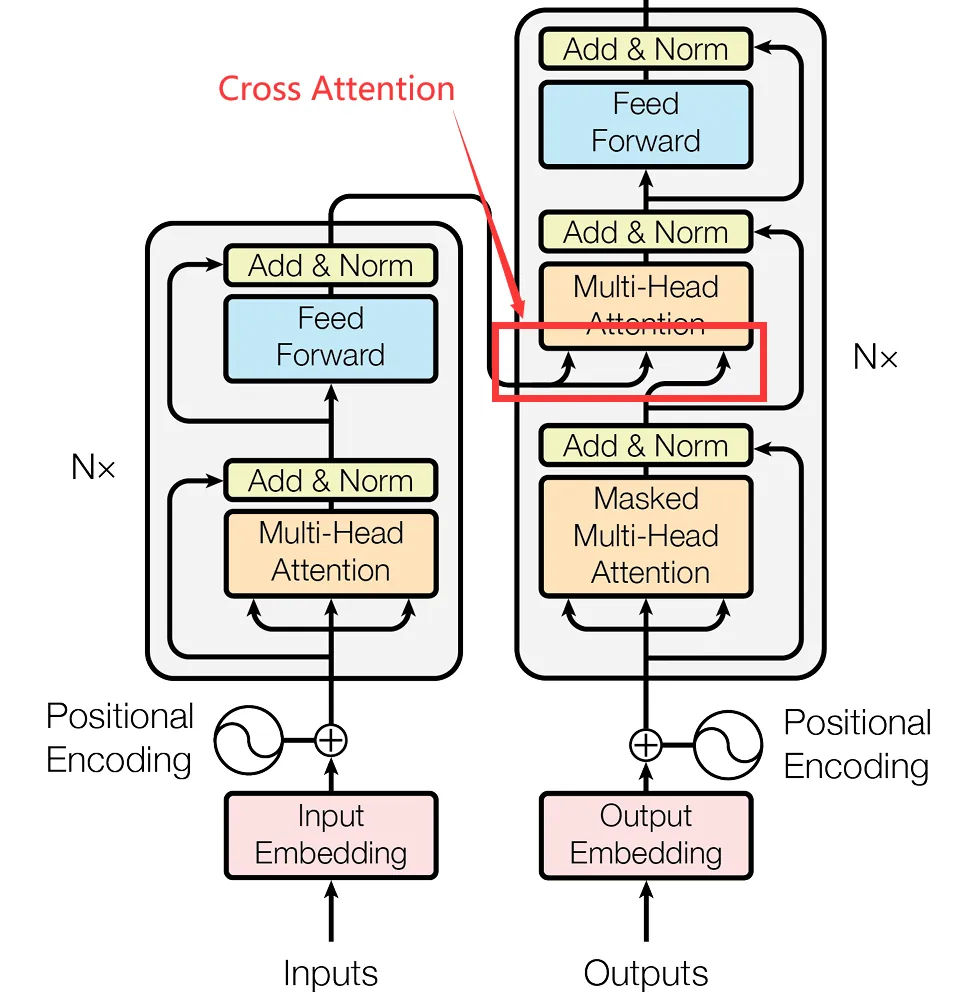
GPT是一种只用到了带掩码自注意力的 Decoder-only 架构 (其实就是扩写),而在标准的Transformer翻译模型中同时存在这两种注意力:
看图中框出的三个箭头,代表这个注意力头的 $Q$ 来自Decoder,$K$ 和 $V$ 来自Encoder处理后的输出,这就是一个Cross-Attention,作为Encoder和Decoder之间的桥梁。什么意思呢?就是Decoder在生成下一个词时,不仅要参考已经生成的输出内容,还需要回到原始输入语义里去查询。比如说英译中,每写一个字都要先看看自己已经写了什么,并回到原始的英文句子对照一下。
用表格归纳一下:
| 组件 | 注意力类型 | Q 来源 | K, V 来源 | 作用 |
|---|---|---|---|---|
| Encoder | Self-Attention | 输入序列自身 | 输入序列自身 | 让输入词彼此理解,形成富含上下文的表示 |
| Decoder | Masked Self-Attention | 已生成的输出序列 | 已生成的输出序列 | 让已生成的词彼此协调 (带掩码) |
| Decoder | Cross-Attention | 已生成的输出序列 | Encoder 的输出 | 让输出词能参考完整的原始输入 |
所谓的"Masked"就是带掩码 (因果掩码) 的意思,保证了模型在训练时不会"作弊"看到未来信息。
具体来说,训练的时候,我们是给把原文输入到 Encoder (对应图中Inputs),译文"答案"完整地输入到 Decoder (对应图中Outputs)。
而到真正推理的时候,我们给Decoder的输入 (Outputs) 是当前已经生成的序列,输出序列的生成是串行的 (一个一个词生成)。
发现问题了吗?训练的时候居然让Decoder看到了完整的答案,这不就相当于看到未来了吗。
我们希望训练时,后面的内容不会影响到前面的词,就得用掩码遮上。
比如说 $n=4$ 的原始矩阵:
$$ M= \begin{bmatrix} q_1 \cdot k_1^T & q_1 \cdot k_2^T & q_1 \cdot k_3^T & q_1 \cdot k_4^T \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & q_2 \cdot k_3^T & q_2 \cdot k_4^T \\ q_3 \cdot k_1^T & q_3 \cdot k_2^T & q_3 \cdot k_3^T & q_3 \cdot k_4^T \\ q_4 \cdot k_1^T & q_4 \cdot k_2^T & q_4 \cdot k_3^T & q_4 \cdot k_4^T \end{bmatrix} $$
我们想让位置1只能看自己,位置2能看1,2,位置3能看1,2,3,位置4能看全部,就可以在softmax处理之前把"不允许看"的位置置为负无穷,这样softmax之后这些位置概率就会变成0。
$$ M'= \begin{bmatrix} q_1 \cdot k_1^T & -\infty & -\infty & -\infty \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & -\infty & -\infty \\ q_3 \cdot k_1^T & q_3 \cdot k_2^T & q_3 \cdot k_3^T & -\infty \\ q_4 \cdot k_1^T & q_4 \cdot k_2^T & q_4 \cdot k_3^T & q_4 \cdot k_4^T \end{bmatrix} $$
你可能会问,那为什么训练的时候为什么不把答案也一点一点输入进去呢,这样就慢了,并行处理当然更好啊,只要遮上"不允许看"的就可以了。
多头注意力
$$\text{MultiHead}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O$$
其中:
$$\text{head}_i = \text{Attention}(X W_i^Q,\; X W_i^K,\; X W_i^V)$$
这里的 $X=\begin{bmatrix} x_1 \\ x_2 \\ \dots \\ x_n \end{bmatrix}$,是由词向量拼成的矩阵。$W^Q,W^K,W^V,W^O$ 都是可以通过学习得到的参数矩阵。
用词向量矩阵 $X$ 乘 $W^Q$ 就能得到前述的 $Q$ 矩阵,乘 $W^K$ 就能得到 $K$ 矩阵,乘 $W^V$ 就能得到 $V$ 矩阵。这就和套函数一样,把词向量当作自变量带入三个函数中分别得到 query, key, value 向量。
每个 head 是一个独立的 Scaled Dot-Product Attention,然后把所有 heads 的结果拼接起来,再用线性变换 $W^O$ 混合整合得到输出,传递给后面层的输入,这就是一个多头注意力模块完成的事。
多头注意力其实就是多个并行的"语义探测器",每个探测器用自己的一套 $Q,K,V$ 去挖掘句子的不同关系,像CNN卷积核的多通道一样,把所有视角融合起来。
位置前馈网络
$$\text{FFN}(x) = \max(0,\; xW_1 + b_1) W_2 + b_2$$
论文中提到的 "Position-wise Feed-Forward Networks",我们知道 $\text{ReLU}(x)=\max(0, x)$,因此"Feed-Forward"结构就是两个线性层之间插入了一个ReLU激活函数。
为什么需要它?注意力不够吗?
注意力负责找"谁和谁相关",而用ReLU引入非线性因素,FFN就提供了非线性表达能力。
同时FFN还能进行特征增强与组合,比如把“主语+动词”组合成新的语义特征。举个例子,输入为[猫, 坐, 在, 垫子],Self-Attention 让"坐"知道"猫"是主语,FFN 则可能把"猫+坐"融合成新特征 (主谓结构)。
网上还有理解是这里两个线性层分别进行了一次升维和降维,使模型能够在高维空间挖掘出更复杂的特征关系:
位置编码
Transformer 的注意力机制本身是不关心谁在前、谁在后的,但显然输入句子[狗 追 猫]和[猫 追 狗]的含义是不同的。
因此序列数据的顺序 (不同Token的位置) 也很重要,于是就有了位置编码 (Positional Encoding),给每个词加一个"位置指纹"。
比如说输入词embedding向量是 $x_i \in \mathbb{R}^{d_{\text{model}}}$ (初始词向量是不带位置信息的),处理出位置编码是 $PE_{pos} \in \mathbb{R}^{d_{\text{model}}}$ (同维度,可直接相加),最终输入$x_i' = x_i + PE_{pos}$,这样就给词向量赋予了位置含义。
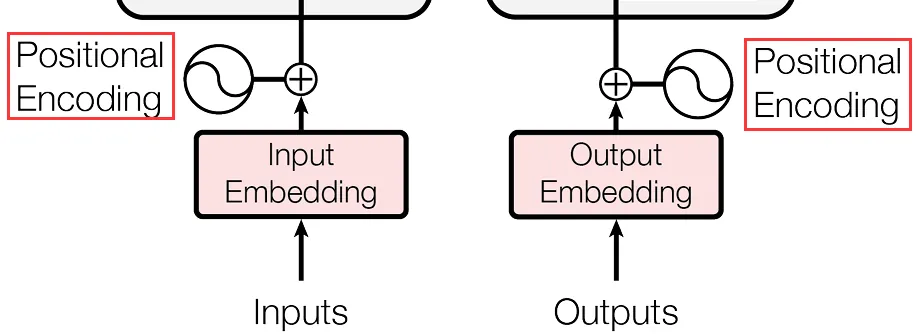
论文中是使用正余弦函数来进行编码的:
$$ \begin{aligned} PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) \\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) \end{aligned} $$
其中:$pos$ 是位置索引 ($0, 1, 2, \dots, n-1$),$2i$ 和 $2i+1$ 是偶/奇数维度索引,$i$ 的范围是从 0 到 $d_{\text{model}}/2 - 1$,$d_{\text{model}}$ 是维度总数。
随着维度的增大,正余弦函数周期从 $2 \pi$ (高频) 到接近 $10000 \cdot 2 \pi$ (低频)。低维由于频率高,$pos$ 的微小变化会使值剧烈变化,有利于捕捉局部细节特征,而高维频率低,有利于捕捉全局趋势。
这样编码的好处还有,相对位置可被线性计算,即存在一个固定的矩阵 $M_k$ (只依赖于偏移量 $k$,与 $pos$ 无关),使得 $PE_{pos+k} = M_k \cdot PE_{pos}$
举个简化例子,假设 $d_{\text{model}} = 2$,则: $$ PE_{pos} = \begin{bmatrix} \sin\left(\frac{pos}{10000^{0}}\right) \\ \cos\left(\frac{pos}{10000^{0}}\right) \end{bmatrix} = \begin{bmatrix} \sin(pos) \\ \cos(pos) \end{bmatrix} $$
而根据三角恒等式: $$ \begin{aligned} \sin(pos + k) &= \sin(pos)\cos(k) + \cos(pos)\sin(k) \\ \cos(pos + k) &= \cos(pos)\cos(k) - \sin(pos)\sin(k) \end{aligned} $$
所以: $$ PE_{pos+k} = \begin{bmatrix} \cos k & \sin k \\ -\sin k & \cos k \end{bmatrix} \cdot PE_{pos} = M_k \cdot PE_{pos} $$
在高维下,这个性质依然近似成立,让模型轻松学到相对位置关系 (如"动词通常在主语后 1~2 位")。
使用正余弦函数还能让值自然归一化到 [-1,1] 范围内,防止位置信息值太大 (甚至远大于embedding语义信息的尺度,那就喧宾夺主了)。
论文中还测试了使用可学习的位置编码,结果发现效果差不多,那不如就直接用现在这个正余弦编码方式了,还能适应不同长度。
总结
再放一遍这个结构图,刚开始可能不完全理解,结合上述内容再多品一品,基本就能完全了解整个结构了。
只要训练的时候投入大量数据,学习好整个网络的参数,推理的时候就根据Output Probabilities确定下一个词是什么。在注意力反复"对照"原文和当前产出的过程中,文本就一点一点生成出来了。
Transformer和CNN一样本质都是特殊连接模式的神经网络,和RNN不同的是带来了并行化设计,使得Transformer能够充分利用GPU/TPU的并行计算能力,解决了训练缓慢问题,这样就可以把参数量做得更大。这场革命不仅带来了训练速度的飞跃和模型性能的突破,更重要的是,它为构建真正"理解"上下文的大模型铺平了道路,也为后来应用于图像和音视频上的任务奠定基础。