计算机视觉上的Transformer ViT
ViT (Vision Transformer) 是Google Brain团队提出的,不依赖CNN,纯Transformer在图像分类上的应用,之前学习了Transformer的原理: Transformer原理学习,这下看看其是如何迁移到计算机视觉任务上的。
论文arxiv链接 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
在ViT出现之前,卷积神经网络 (CNN) 是计算机视觉领域的主流架构。ViT论文在Introduction中就指出,在像ImageNet这样中等大小的数据集上训练时,效果不如同等规模的ResNet模型,作者将其归因于缺少如CNN那样的归纳偏置。而在足够大的数据集 (14M-300M images) 上训练时,ViT的表现就会超过CNN。
ViT的总体结构图如下:
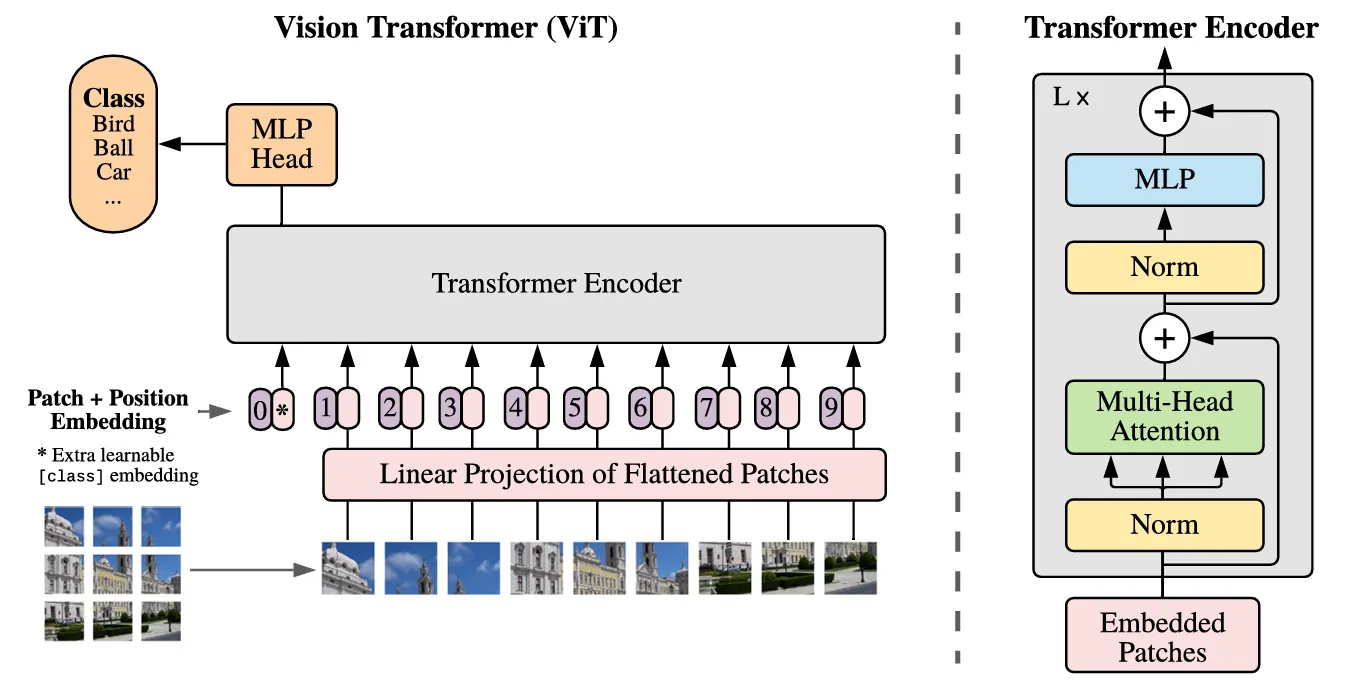
将图像转化为序列
我们知道Transformer最早是应用于NLP文本序列上的,那么如何把一张图像转化为序列问题呢?
论文中提到,若直接将自注意力机制应用于图像,让每个像素关注所有其他像素,这种计算复杂度随像素数量呈平方增长,并不现实。因此,在此之前人们曾尝试过多种近似方案,比如说仅将自注意力应用于每个查询像素的局部邻域而非全局范围。与ViT最接近的一种方法是,从输入图像中提取2x2尺寸的图像块,并在其上应用全局自注意力机制。
采用2x2像素的小尺寸图像块会导致模型仅适用于低分辨率图像,ViT的工作则更进一步,处理了中等分辨率图像,并证明大规模预训练有望使Transformer模型超越最先进的CNN模型。
具体来说,ViT的做法是,将一张图像 (尺寸 $H\times W \times C$,$C$ 是通道数) 切成一些固定大小 ($P \times P$) 的图像块 (patches),看这个有趣的论文标题为"An Image is Worth 16x16 Words",就知道 $P=16$,那么 $N = \frac{HW}{P^2}$ 为图像块的数量,每个图像块维度为 $P^2 \cdot C$。
然后通过一个线性投影 (可学习的嵌入层) 将每个图像块映射到一个维度为 $D$ 的embedding向量。
添加位置编码
和文本序列一样,也需要加入位置编码,ViT和原版Transformer的正余弦位置编码不一样,使用了可学习的位置嵌入,然后与patch embedding相加。
论文后面做了一个对照实验,分别使用不同类型的位置编码:
-
无位置编码
-
1-D 位置编码:把2-D的patches看成1-D序列,相当于展平了,只用一个位置编码嵌入表
-
2-D 位置编码:考虑patches的2-D位置 $(x, y)$,学习两个独立的嵌入表 (X-embedding和Y-embedding),再拼接在一起 $\mathbf{e}_{(x,y)} = \operatorname{concat}\big(\mathbf{e}^x_X,\; \mathbf{e}^y_Y\big)$
-
相对位置编码:将patchs的相对位置偏置融入注意力机制
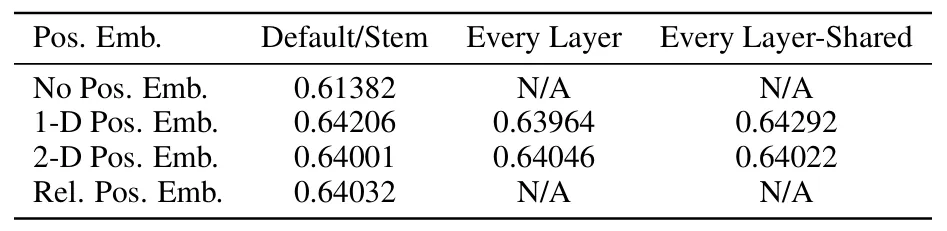
可见,虽然无位置嵌入模型与含位置嵌入模型之间存在显著性能差距,但不同位置信息编码方式之间差异甚微,这表明1D位置编码已足够好。
论文中推测,由于Transformer编码器处理的是块级输入而非像素级输入,空间信息的编码方式差异影响较小。
因此只用1D可学习位置编码就可以了。
CLS Token
也就是Class Token,ViT借鉴了NLP中BERT的做法,在输入序列开头插入一个特殊的、无实际内容的token,让它在多层自注意力中"吸收"所有其他token的信息,经过多层Transformer的作用,CLS Token的表示逐渐融合了全局语义信息,最终用它的输出作为整张图像类别特征的代表。
那么能不能不加这个CLS Token呢?这个在论文后面也有提到。
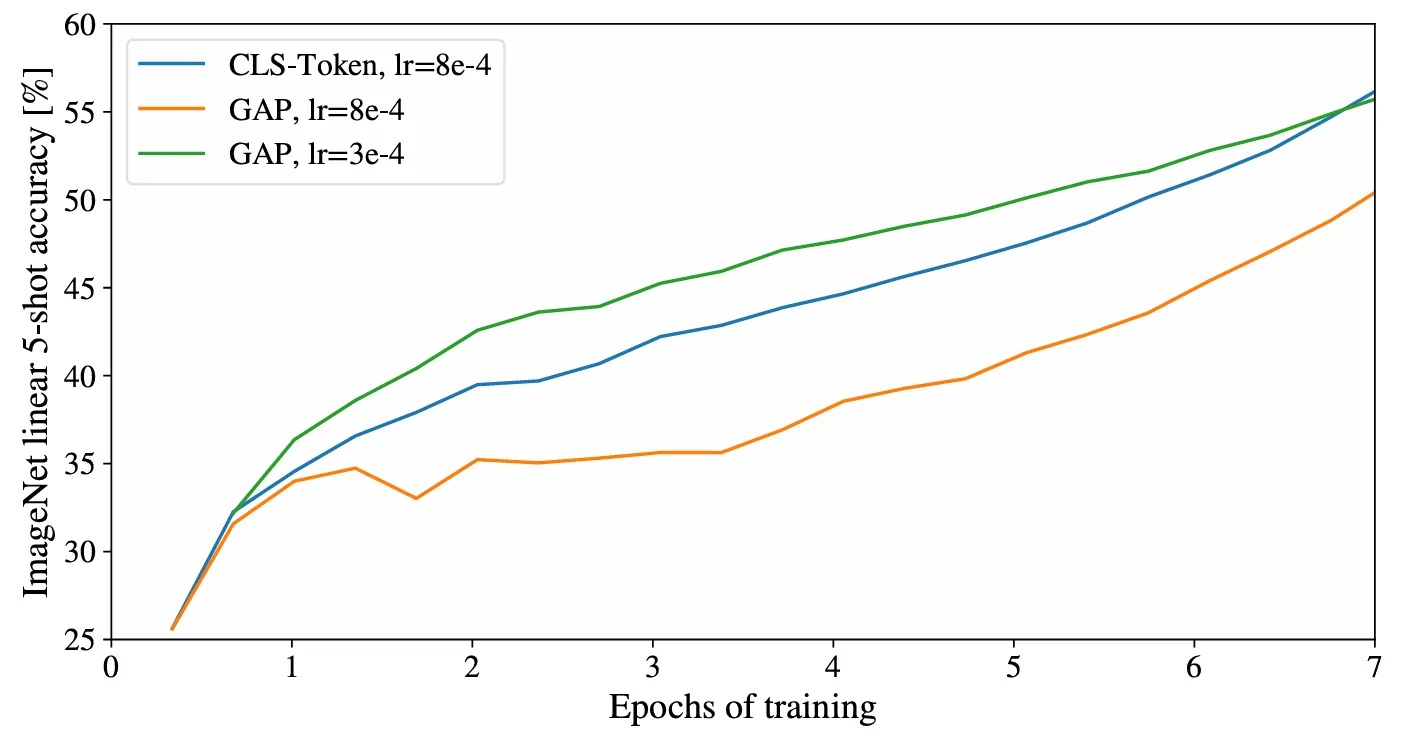
ViT早期尝试采用patch embeddings取平均的方法,经全局平均池化 (GAP, globally average-pooling) 处理后接分类器,发现效果不太好。
但他们发现问题既非源于CLS Token的有无,亦非GAP操作所致,而是由所需学习率 (lr, learning rate) 差异导致的,也就是调整好参数也能达到一个比较好的效果,如下图所示:
编码器
ViT是Encoder-only结构,只有编码器,标准的多头注意力。
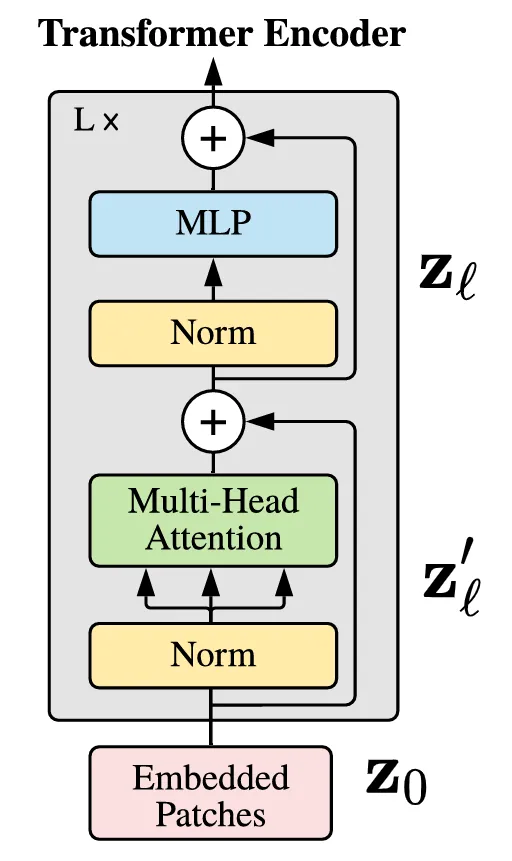
$$ \begin{align} \mathbf{z}_0 &= \left[ \mathbf{x}_{\text{class}};\, \mathbf{x}_p^1 \mathbf{E};\, \mathbf{x}_p^2 \mathbf{E};\, \dots;\, \mathbf{x}_p^N \mathbf{E} \right] + \mathbf{E}_{\text{pos}}, & \mathbf{E} &\in \mathbb{R}^{(P^2 \cdot C) \times D},\ \mathbf{E}_{\text{pos}} \in \mathbb{R}^{(N+1) \times D} \\ \mathbf{z}'_\ell &= \operatorname{MSA}\bigl( \operatorname{LN}(\mathbf{z}_{\ell-1}) \bigr) + \mathbf{z}_{\ell-1}, & \ell &= 1, \dots, L \\ \mathbf{z}_\ell &= \operatorname{MLP}\bigl( \operatorname{LN}(\mathbf{z}'_\ell) \bigr) + \mathbf{z}'_\ell, & \ell &= 1, \dots, L \\ \mathbf{y} &= \operatorname{LN}(\mathbf{z}_L^0) \end{align} $$
其中 $\operatorname{LN}$ 指的是Layer Normalization (层归一化),$\operatorname{MSA}$ 就是Multi-Head Self-Attention,$\operatorname{MLP}$ 包括两层全连接网络 + GELU 激活,也就是 $\mathrm{MLP}(\mathbf{x}) = \mathrm{GELU}(\mathbf{x} \mathbf{W}_1 + \mathbf{b}_1) \mathbf{W}_2 + \mathbf{b}_2$。
下标 $\ell$ 指的是Encoder层索引,也就是总共有 $L$ 个这样的Encoder串在一起。
然后注意一下初始嵌入 ($\mathbf{z}_0$),$\mathbf{E}$ 就是Patch Embedding矩阵,可以将每个patch映射到 $D$ 维空间。$\mathbf{E}_{\text{pos}}$ 就是可学习的位置编码。$\mathbf{x}_{\text{class}}$ 是一个前面提到的Class Token向量,用于分类。
取最后一层Encoder输出的第一个token也就是CLS Token,然后经过一次层归一化,得到分类输出 $\operatorname{LN}(\mathbf{z}_L^0)$。将这个 $\mathbf{y}$ 送入一个分类头 (通常是单层线性变换 + 非线性函数) 就可以得到类别概率。
模型可视化
论文里还给了一些可视化的图,如下:
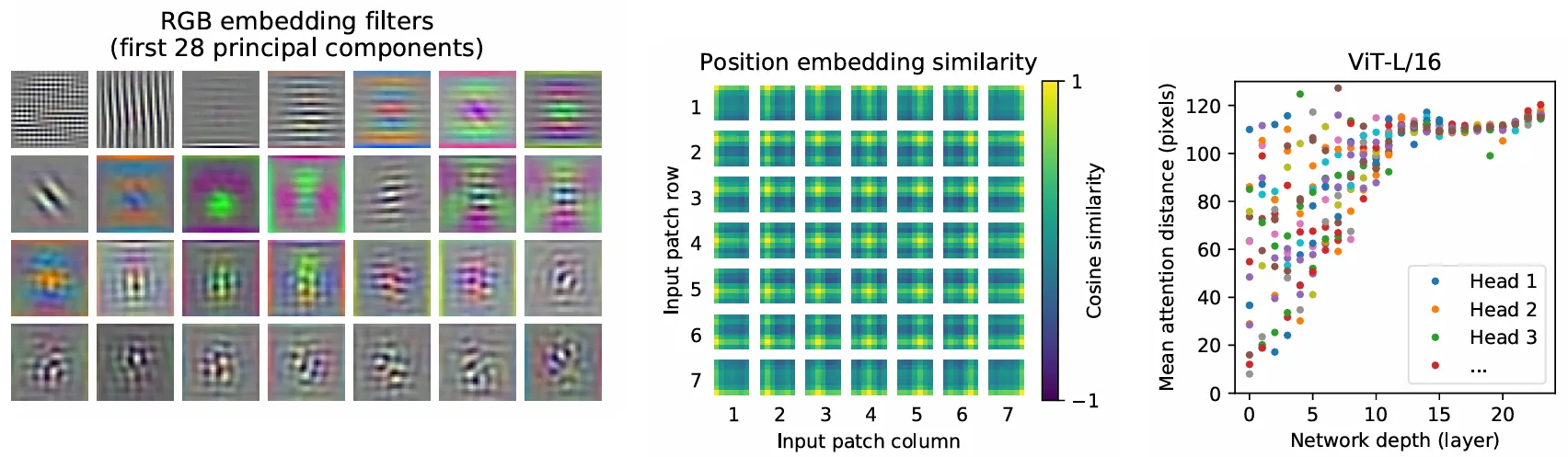
左图是初始线性嵌入滤波器 (Linear Projection) 的前28个主成分,和CNN学到的很像,说明ViT也能学到一些基础视觉基元。
中图是模型位置嵌入的相似性分布,每个小热力图展示了这个位置的patch与所有patch的位置嵌入向量之间的余弦相似度。可以发现每个patch的位置embedding向量都与同一行/列的patch比较相似。
右图是注意力区域大小随网络深度的变化,纵轴是Mean attention distance,每个点表示一个注意力头的平均注意力距离,Attention distance是一个查询像素与所有其他像素间的距离 (以注意力权重) 加权平均获得的,那么平均注意力距离就反映了注意力的范围,刚开始就能注意到10-110像素,而相比之下CNN刚开始第一层的感受野很小,只能看到附近的像素。
原文中描述,在底层网络中,各注意力头间的平均注意力距离差异显著:部分注意力头覆盖图像大部分区域,而另一些则仅关注查询位置附近的小范围区域。随着网络深度增加,所有头部的注意力距离均呈增长趋势。在网络后半部分,多数头部注意力覆盖显著扩大。
论文中还用一种叫Attention Rollout的方法,很酷的可视化,展示了模型推理时真正"关注"的区域:
