请求分析
首先,我们还是先打开开发者工具,然后打开Google翻译(translate.google.cn),
接着,我们随便输入一些内容,点击小喇叭朗读,便可以很轻松地抓取到如下请求:
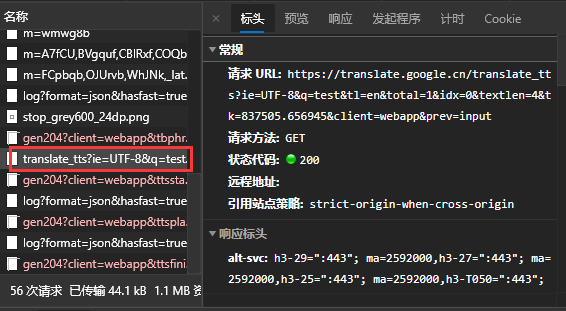 观察GET参数,找出几个重要的参数(实际上textlen是不需要的):
观察GET参数,找出几个重要的参数(实际上textlen是不需要的):
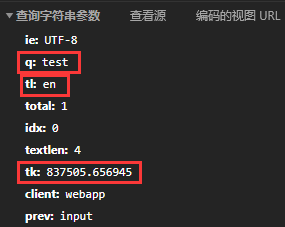 又是熟悉的tk参数,我们在上一篇文章中分析过tk的获取。
又是熟悉的tk参数,我们在上一篇文章中分析过tk的获取。
根据我们上次的经验,我们可以知道:q为源文本,tl为朗读的语言,tk为验证参数。
tk值算法的验证
那么到底这里的tk值和之前那个算法得到的一不一样呢?
我们将之前的tk算法获取的tk值代入请求链接(将原来的tk参数换成得到的),使用浏览器访问,经过验证,发现是可以得到音频的,所以tk算法并没有改变。
于是tk值的获取便解决了。
代码编写
分析到这里,就非常简单了。
最终代码如下:
def getGoogleToken(a, TKK): #tk算法
def RL(a, b):
for d in range(0, len(b)-2, 3):
c = b[d + 2]
c = ord(c[0]) - 87 if 'a' <= c else int(c)
c = a >> c if '+' == b[d + 1] else a << c
a = a + c & 4294967295 if '+' == b[d] else a ^ c
return a
g = []
f = 0
while f < len(a):
c = ord(a[f])
if 128 > c:
g.append(c)
else:
if 2048 > c:
g.append((c >> 6) | 192)
else:
if (55296 == (c & 64512)) and (f + 1 < len(a)) and (56320 == (ord(a[f+1]) & 64512)):
f += 1
c = 65536 + ((c & 1023) << 10) + (ord(a[f]) & 1023)
g.append((c >> 18) | 240)
g.append((c >> 12) & 63 | 128)
else:
g.append((c >> 12) | 224)
g.append((c >> 6) & 63 | 128)
g.append((c & 63) | 128)
f += 1
e = TKK.split('.')
h = int(e[0]) or 0
t = h
for item in g:
t += item
t = RL(t, '+-a^+6')
t = RL(t, '+-3^+b+-f')
t ^= int(e[1]) or 0
if 0 > t:
t = (t & 2147483647) + 2147483648
result = t % 1000000
return str(result) + '.' + str(result ^ h)
word='test'
lan='en'
word2=word
if " " in word:
word2=word.replace("%20"," ") #空格转义
tk=getGoogleToken(word,'442788.2585626513') #tk获取,详细参考上篇文章
url="https://translate.google.cn/translate_tts?ie=UTF-8&q="+word2+"&tl="+lan+"&total=1&idx=0&textlen="+str(len(word))+"&tk="+tk+"&client=webapp"
#实际上textlen可省去
print(url)
这里不需要引用任何库,即可获取TTS音频链接。
如果需要获取后下载的,请自行扩展。