请求分析
首先,打开开发者工具,访问有道翻译。
和前面几篇爬取翻译类似,还是先输入一些文本,抓取请求:
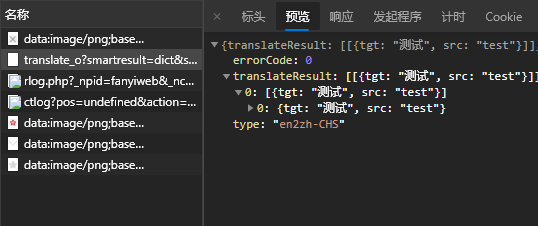
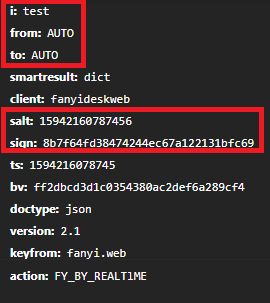
salt和sign获取
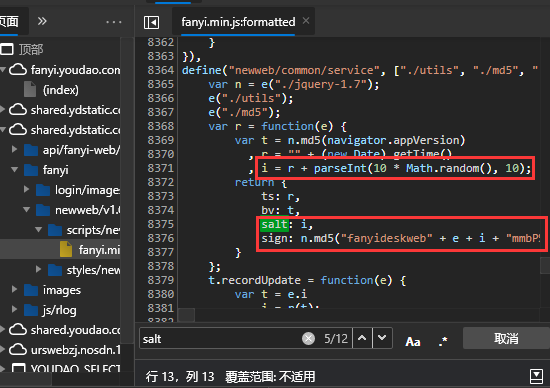 在
在fanyi.min.js中,我们居然能够通过搜索得到salt和sign的算法,真是一举两得啊。
关键js代码如下:
var n = e("./jquery-1.7");
e("./utils");
e("./md5");
var r = function(e) {
var t = n.md5(navigator.appVersion)
, r = "" + (new Date).getTime()
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "mmbP%A-r6U3Nw(n]BjuEU")
}
};
于是从中我们可以清楚地得知,salt的计算方法为(new Date).getTime()+parseInt(10 * Math.random(),10),
转换成python代码,也就是salt = int(time.time()*1000) + random.randint(0,10)
而sign则是为n.md5("fanyideskweb" + e + i + "mmbP%A-r6U3Nw(n]BjuEU")
转换成python代码,为'fanyideskweb'+ key + str(salt) +'mmbP%A-r6U3Nw(n]BjuEU'的MD5值。
由此,我们可以得出具体的算法代码:
def getSalt():
import time, random
salt = int(time.time()*1000) + random.randint(0,10)
return salt
def getMD5(v):
import hashlib
md5 = hashlib.md5()
md5.update(v.encode("utf-8"))
sign = md5.hexdigest()
return sign
def getSign(key, salt):
sign = 'fanyideskweb'+ key + str(salt) +'mmbP%A-r6U3Nw(n]BjuEU'
sign = getMD5(sign)
return sign
完整代码
def getSalt():
import time, random
salt = int(time.time()*1000) + random.randint(0,10)
return salt
def getMD5(v):
import hashlib
md5 = hashlib.md5()
md5.update(v.encode("utf-8"))
sign = md5.hexdigest()
return sign
from urllib import request, parse
import urllib,re,json
def getSign(key, salt):
sign = 'fanyideskweb'+ key + str(salt) +'mmbP%A-r6U3Nw(n]BjuEU'
sign = getMD5(sign)
return sign
def youdao(key,fromm,tom):
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
salt = getSalt()
data = {
"i": key,
"from":fromm,
"to": tom,
"smartresult": "dict",
"client": "fanyideskweb",
"salt": str(salt) ,
"sign": getSign(key, salt),
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action":"FY_BY_REALTIME",
"typoResult": "false"
}
#print(data)
data = parse.urlencode(data).encode()
headers = {
"Accept": "application/json,text/javascript,*/*;q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": len(data),
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8",
"Cookie": "[email protected];JSESSIONID=aaaQ3mQcC0ClHfrr5PUmx;OUTFOX_SEARCH_USER_ID_NCOO=1831494261.899505;___rl__test__cookies=1594217695802",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4188.0"
}
req = request.Request(url=url, data=data, headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
#print(html)
return json.loads(html)
res=youdao('test','en','zh-CHS')
print(res)
值得注意的是,cookie是不可省去的(可以使用自己在浏览器复制的cookie,或者使用我的也可以)。
语言代码
| 语言 | 代码 |
|---|---|
| 中文 | zh-CHS |
| 英语 | en |
| 日语 | ja |
| 韩语 | ko |
| 法语 | fr |
| 德语 | de |
| 俄语 | ru |
| 西班牙语 | es |
| 葡萄牙语 | pt |
| 意大利语 | it |
| 越南语 | vi |
| 印尼语 | id |
| 阿拉伯语 | ar |
但是,有道翻译只支持中文和各国语言互转,并不是支持各国语言互转。
后续问题
根据我的分析,sign的算法是会改变的。比如说我们刚才的'mmbP%A-r6U3Nw(n]BjuEU'是一个随机值,有道翻译会不定时更新。
但是,其他部分是不变的,也就是sign为'fanyideskweb'+ key + str(salt)再加上一个随机字符串的的MD5值。
那么,一条新的思路又出来了:只要js路径不变,我们就可以自动从js源代码中提取出这个随机字符串,实现自适应功能。
最简单的实现方法就是根据两边文本提取中间文本。
实现代码如下:
def getsp():
url="http://shared.ydstatic.com/fanyi/newweb/v1.0.27/scripts/newweb/fanyi.min.js"
page = urllib.request.urlopen(url)
contents = page.read()
reg = "sign:n.md5((.*?))}};"
tmp = re.findall(reg, str(contents)) #这里是分步提取,其实写麻烦了
pos1=str(tmp[0]).find("+e+i+")+6
pos2=str(tmp[0]).find(")',")-1
ss=str(tmp[0])[pos1:pos2] #截取中间部分,也可以使用正则
#print(ss)
return ss
然后我们将getSign函数稍作修改即可:
def getSign(key, salt):
sign = 'fanyideskweb'+ key + str(salt) +getsp()
#sign = 'fanyideskweb'+ key + str(salt) +'mmbP%A-r6U3Nw(n]BjuEU'
sign = getMD5(sign)
return sign
然而,后来我发现js路径也会改变。不过这个随机字符串刷新的频率要更快,因此这个自适应还是有一定作用的。
实际上,我们还可以根据网页源代码提取出这个js的路径。但是如果有道翻译哪天全新改版就要重新寻找算法了。