之前我们爬取过中国天气网,但是其数据并不全面,且只有国内天气,我最近发现和风天气包含全世界的天气数据,真是一个不错的数据源,让我们来爬取它的数据吧。
打开浏览器开发者工具,打开和风天气网页,例如北京市天气:
https://www.qweather.com/weather/beijing-101010100.html
来看看有哪些网络请求:
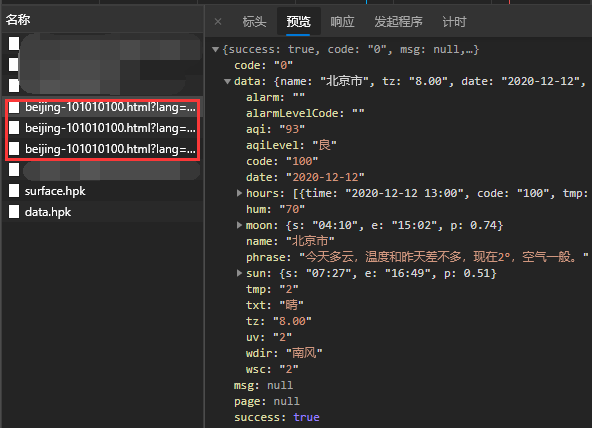 根据经验,这三个请求是最可能有用的。
根据经验,这三个请求是最可能有用的。
查看第一个请求返回的json数据,可以猜出来是当前的天气数据。
再看看请求链接:
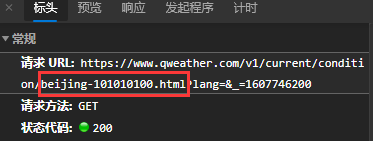 请求url为
请求url为https://www.qweather.com/v1/current/condition/beijing-101010100.html,
此处的beijing-101010100应该是城市的一个编号。
继续分析,网页中有未来7日的预报
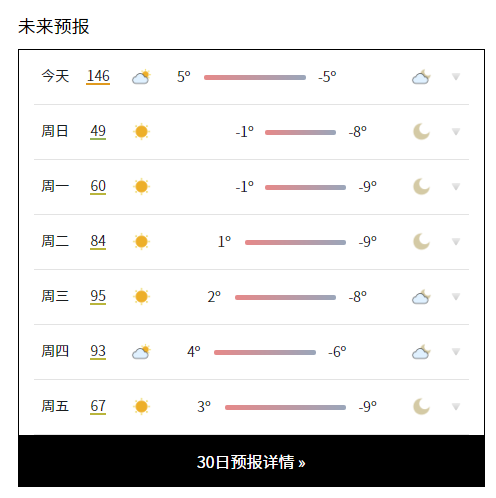 既然没有抓到有关未来预报的json,很可能这些数据是直接包含在网页源代码中。
既然没有抓到有关未来预报的json,很可能这些数据是直接包含在网页源代码中。
寻找一下,果然是这样:
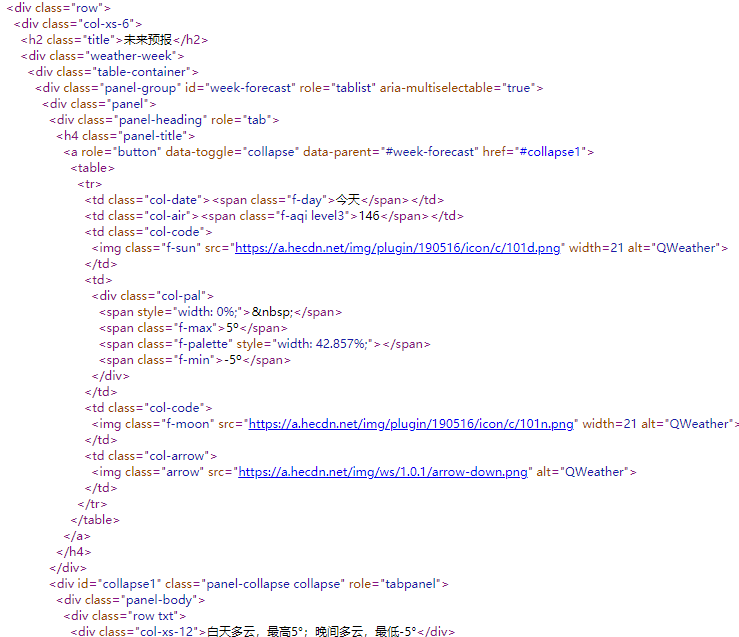 现在我们就有爬取天气数据的思路了,首先我们要获取到要查询的城市的编号,拼接url,从一个接口中获取该城市当前的天气数据,
现在我们就有爬取天气数据的思路了,首先我们要获取到要查询的城市的编号,拼接url,从一个接口中获取该城市当前的天气数据,
再通过网页源代码抓到未来7日的天气数据,最后整合得到最终结果。
那么,如何得到城市的编号呢?
左上角有个搜索栏,我们搜索一下上海,会出现很多条结果:
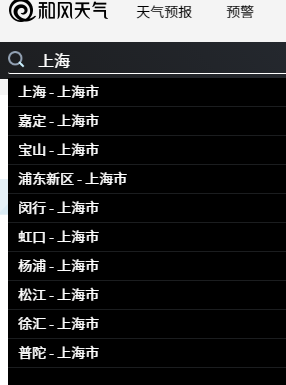 同时,能够抓取到json数据,
同时,能够抓取到json数据,
请求url是https://geoapi.heweather.net/find?key=bdd98ec1d87747f3a2e8b1741a5af796&location=上海
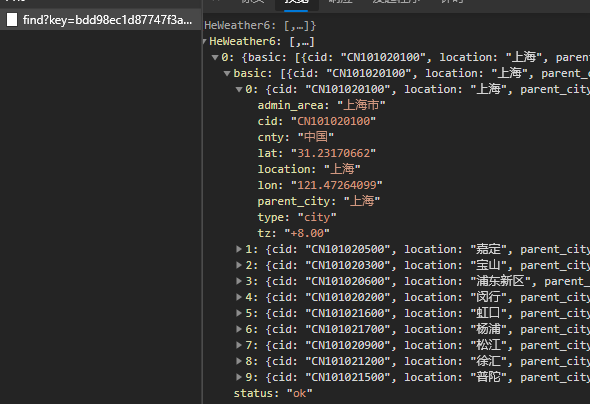 其中,每条结果都有一个cid,但是这个请求需要key参数,查看发起程序,找到
其中,每条结果都有一个cid,但是这个请求需要key参数,查看发起程序,找到https://www.qweather.com/js/weather-city.min.js,在这个js中,搜索key,可以发现key就包含在这个js里面,是固定的一个值。
接着选择保留日志,点击一下第一条,再看看,发现了一个请求:
 该请求返回的结果是
该请求返回的结果是shanghai-101020100,再看看网页的链接:
 发现了吗,这得到的正是城市的编号。
发现了吗,这得到的正是城市的编号。
于是,我们获取编号的思路就有了:首先获取城市关键词搜索结果,得到第一条结果的cid,再通过最后我们得到的那个请求url获取城市编号。
至此,所有分析都完成了,接下来就是用python来实现这个过程。
使用requests发送get请求,json数据使用json库loads,解析html可以使用beautifulsoup、lxml等(或者正则也可以),
具体思路已经很明确了,很容易实现,代码就不给出了。